- Published on
AI探秘-模型微调我懂你了!!!
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
目录
在AI探秘-理解模型预训练中,我们了解了如何通过预训练得到基座模型。预训练模型虽然具备较强的语言理解与生成能力,但在实际应用中,通常还需要针对具体任务、领域或行为目标进行微调(Fine-tuning),才能获得更好的效果。
微调是指在预训练模型的基础上,使用相对较小的任务数据或领域数据继续训练,使模型更好地适应特定任务、领域或行为目标。
指令微调
指令微调(Instruction Tuning)是一种用于下游任务适配的重要方法。其核心思想是利用“指令—响应”数据对预训练模型进行微调,使模型能够更好地理解和遵循自然语言指令,从而完成多种下游任务。
与传统面向单一任务的监督微调不同,指令微调更强调模型对自然语言指令的理解与泛化能力,因此通常能够提升模型的多任务适应性。
指令微调的基本流程
指令微调通常依赖高质量的指令数据,并通过监督微调(Supervised Fine-Tuning,SFT)来训练模型。其基本流程通常包括以下两个步骤:
- 指令数据构建:构造包含指令及其对应输出的训练数据。
- 监督微调:基于标注好的指令数据对预训练模型进行训练。
由于全参数监督微调通常需要较高的计算资源和显存开销,因此在实际应用中,常采用参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)方法,以减少可训练参数数量并降低微调成本。
参数高效微调(PEFT)
参数高效微调通过避免更新全部模型参数,减少训练时需要优化的参数量和计算开销,从而提升大模型微调的效率。
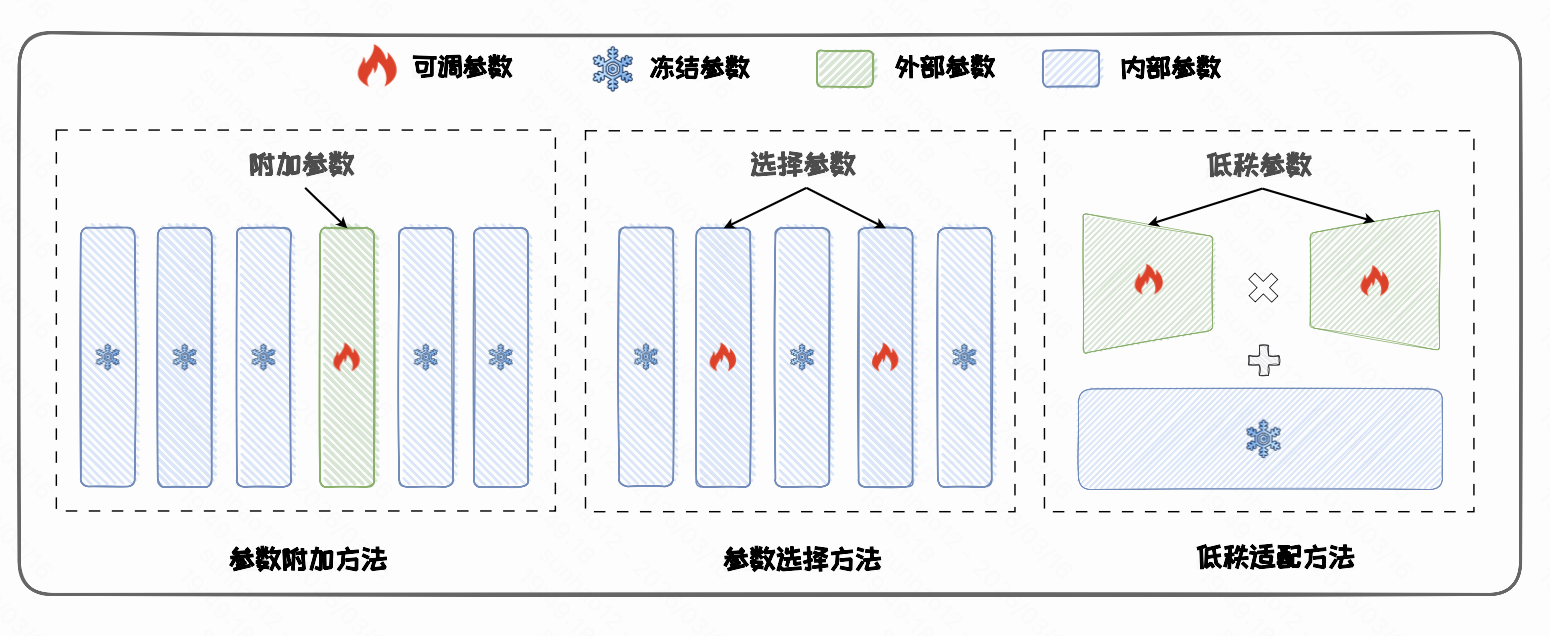
常见的 PEFT 方法可以粗略分为以下几类:
- 参数附加方法(Additional Parameter Methods)
- 参数选择方法(Parameter Selection Methods)
- 低秩适配方法(Low-Rank Adaptation Methods)
参数附加方法
参数附加方法(Additional Parameter Methods)通过在模型中引入新的、较小的可训练模块,实现对预训练模型的高效适配。在微调过程中,通常冻结原始模型参数,仅更新这些新增参数。
常见的参数附加方法包括:
- 适配器微调(Adapter-tuning)
- 提示微调(Prompt-tuning)
- 前缀微调(Prefix-tuning)
- 代理微调(Proxy-tuning)
从作用位置来看,这类方法可以粗略理解为三类:
- 加在输入
- 加在模型
- 加在输出或解码阶段
加在输入:Prompt-tuning
加在输入的方法将额外参数附加到模型的输入嵌入(Embedding)中,Prompt-tuning 就属于这一类方法。
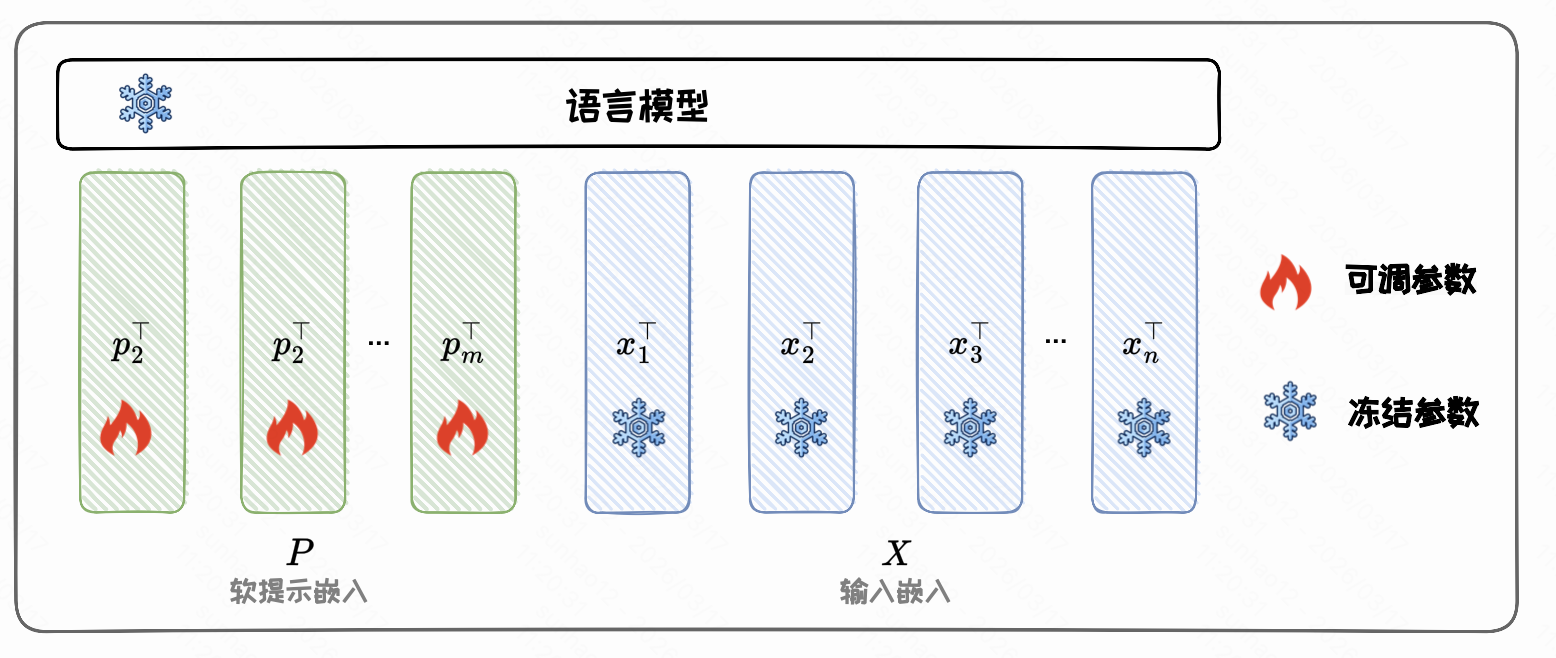
提示嵌入(Prompt Embedding)是一种典型的参数附加方式。它通过在输入序列前加入可训练的提示向量,引导模型完成特定任务。在训练过程中,原始模型参数保持不变,仅更新提示嵌入;在推理阶段,通过使用训练得到的提示嵌入,可以在不修改原始模型参数的前提下控制模型行为。
加在模型:Prefix-tuning
Prefix-tuning 也是一种常见的参数附加方法。与 Prompt-tuning 主要作用于输入不同,Prefix-tuning 会为 Transformer 每一层的注意力模块引入可学习的前缀表示。
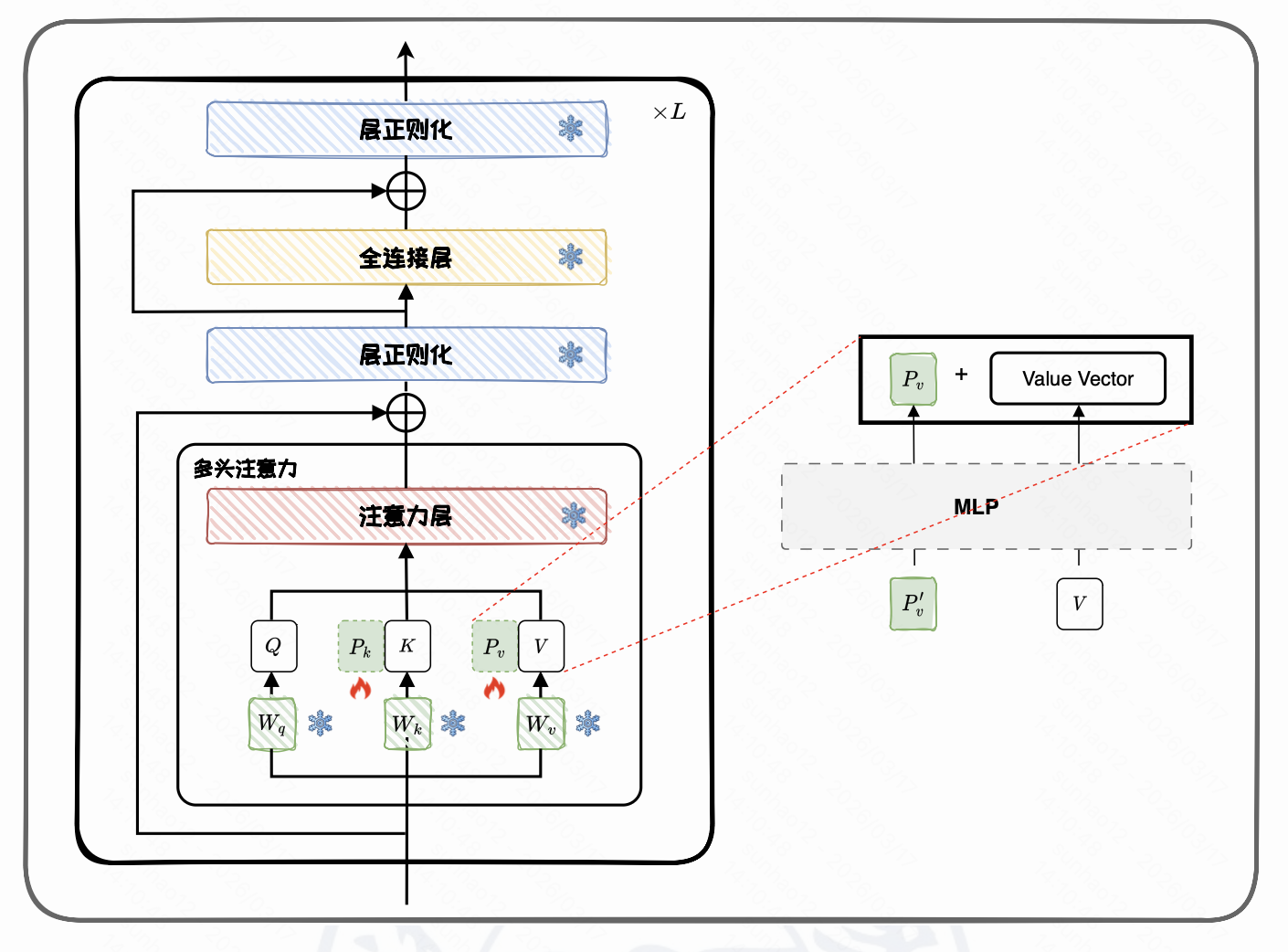
这些前缀通常以额外的 key/value 前缀形式参与注意力计算。在训练过程中,仅更新这些前缀参数,而原始模型参数保持不变。通过这种方式,模型能够在不进行全参数微调的情况下适应新任务。
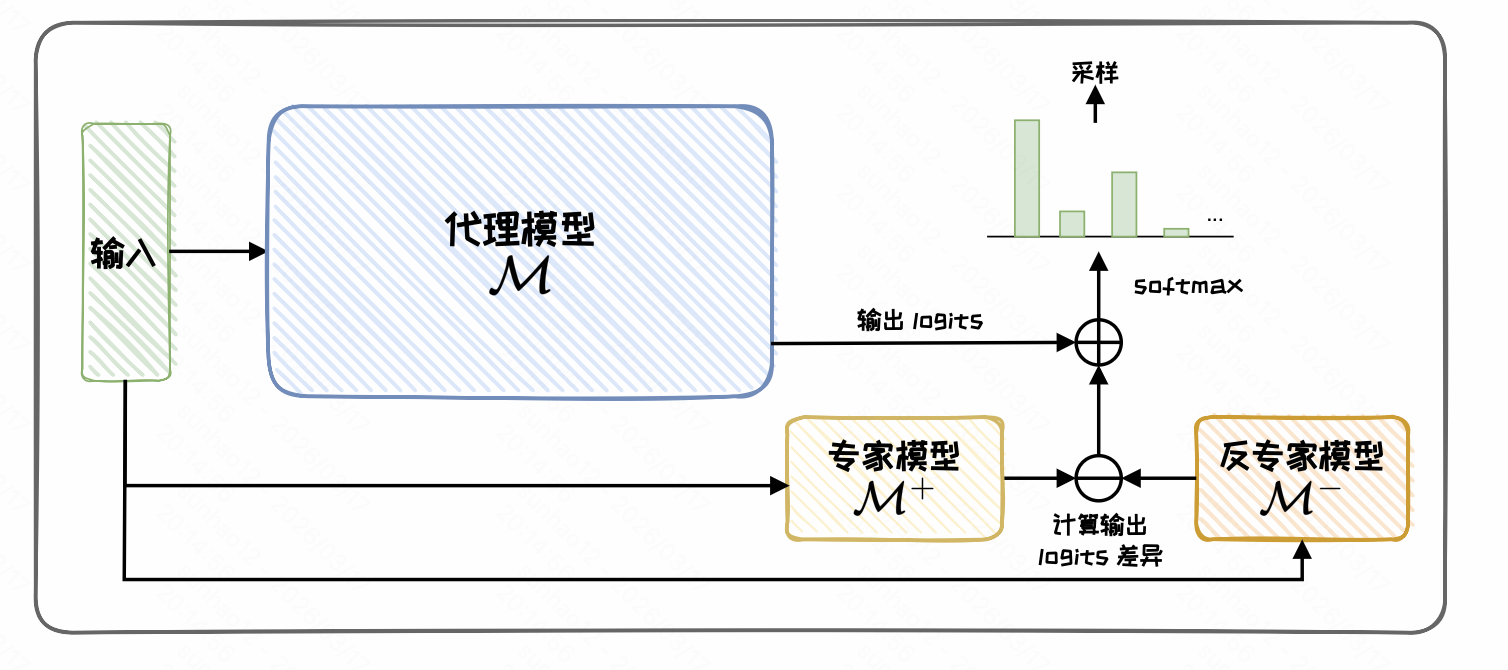
加在输出:Proxy-tuning
与前面通过新增可训练参数进行适配的方法不同,代理微调(Proxy-tuning)更侧重于在解码阶段对模型输出进行调整。
代理微调(Proxy-tuning)提供了一种轻量级的解码时(decoding-time)方法,允许我们在不直接修改大语言模型权重的前提下,仅通过访问模型输出的词汇表预测分布,对大语言模型进行进一步定制化调整。
参数选择方法
参数选择方法(Parameter Selection Methods)仅选择模型的一部分参数进行微调,而冻结其余参数。这类方法利用模型中不同参数的重要性差异,只对部分关键参数进行更新,以降低训练成本。
常见的参数选择方法包括:
- BitFit
- Child-tuning
从选择方式来看,这类方法通常可以分为两类:
- 基于规则的方法
- 基于学习的方法
基于规则的方法:BitFit
基于规则的方法根据人工经验或预先设定的规则,确定哪些参数参与更新。BitFit 是其中较有代表性的方法。
BitFit 通过仅优化神经网络各层中的偏置项(bias)以及任务特定的分类头,实现参数高效微调。尽管可训练参数极少,但在某些任务中仍能取得不错的效果。
基于学习的方法:Child-tuning
基于学习的方法会在训练过程中自动选择可训练的参数子集。Child-tuning 是这一方向的代表方法之一。
Child-tuning 通过梯度掩码机制,仅允许选中的子网络参数接收梯度更新,而屏蔽其他参数的梯度,从而实现对可训练参数子集的自动选择。
低秩适配方法
低秩适配方法(Low-Rank Adaptation Methods)通过低秩矩阵来近似原始权重更新矩阵,并冻结原始参数矩阵,仅微调低秩更新部分,从而减少微调时的显存和计算开销。
常见的低秩适配方法包括:
- LoRA
- AdaLoRA
- QLoRA
- DoRA
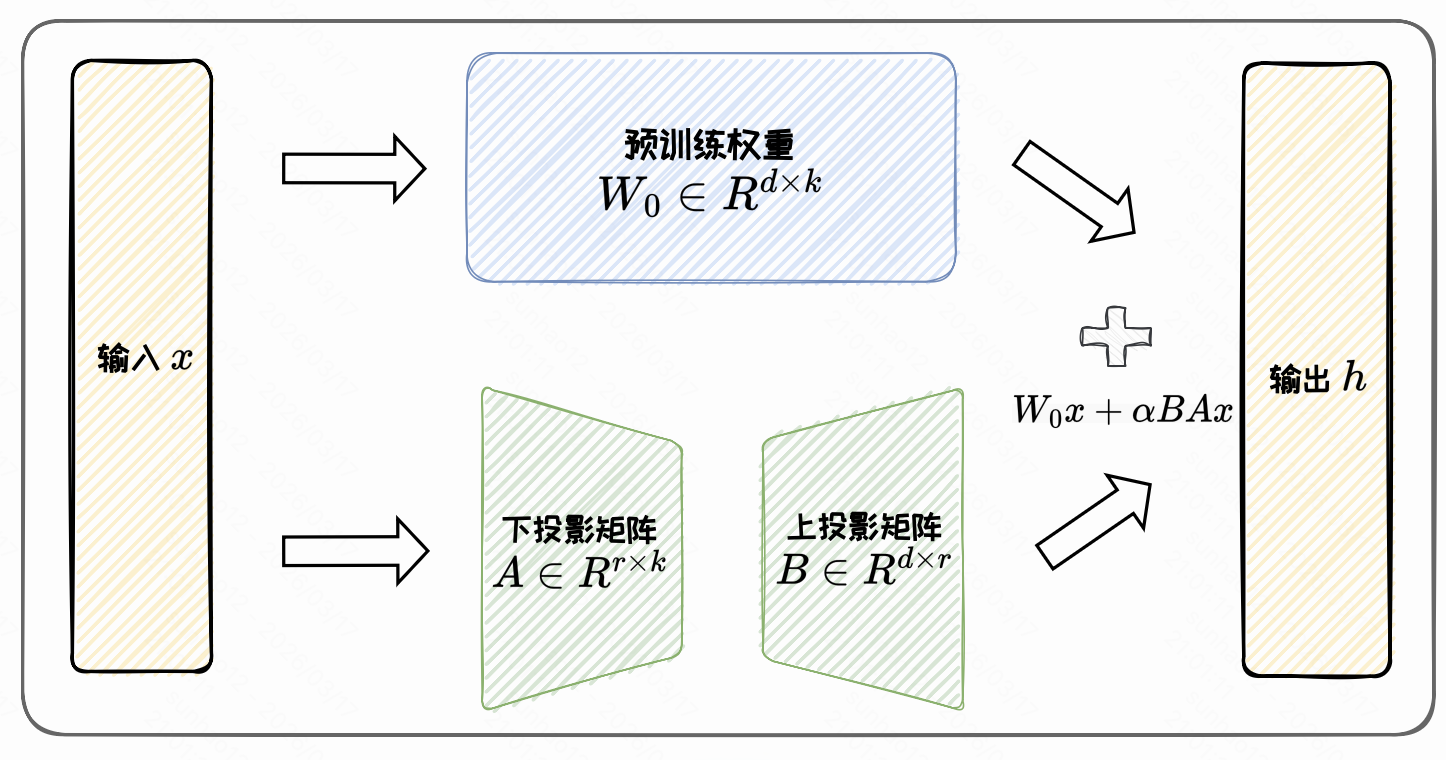
参数高效微调框架
Hugging Face 开发的开源库 PEFT 提供了多种参数高效微调方法的统一接口,便于开发者快速实践 LoRA、Prompt-tuning、Prefix-tuning 等方法。