- Published on
AI探秘-理解模型预训练
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
📚 目录
前置概念
训练过程
在AI探秘-理解大模型注意力机制中,我们了解自注意力包含可训练权重,优化这些权重会直接影响模型的生成效果。
在模型训练中采用右移对齐: 对于序列中每个位置 i, 模型输出该位置的 logits 向量 (未归一化分数), 表示对"下一个 token"的评分。 通过目标 token 与 logits 计算交叉熵损失进行反向传播以更新参数提高模型生成效果。

前置概念
困惑度(Perplexity)
Perplexity(PPL)是衡量语言模型在“下一个 token 预测”任务上困惑程度的指标,定义为平均交叉熵损失的指数:
PPL = exp(loss)
含义:模型在每个 token 上平均“犹豫的选项数”,越低越好;PPL=1 表示几乎完美预测。
交叉熵损失
交叉熵损失(Cross-Entropy)是训练与验证最常用的目标函数,用于衡量预测分布与真实分布的差异。
批次(Batch)
批次(Batch)是指一次前向传播和反向传播中同时处理的多个训练样本(序列)的集合。
- 批次大小(batch size):一个批次包含的样本数量,例如 batch_size=8 表示每次处理 8 个序列
- 为什么用批次:
- 效率:并行处理多个样本,充分利用 GPU/TPU 的并行计算能力
- 稳定性:批次内多个样本的梯度求平均,使梯度更新更稳定,减少单样本噪声
- 内存平衡:批次大小影响显存占用;更大的 batch 需要更多内存,但训练可能更稳定
- 训练流程:整个训练集被分成多个批次,逐个批次处理:前向计算 → 计算损失 → 反向传播 → 更新参数
训练过程
构建训练集/验证集
训练集
计算损失并做反向传播,直接更新模型参数。
构建方式:
- 文档打包:将多个文档顺序拼接,文档边界插入
<eos>。 - 切块长度:设定
block_size,将长序列等长切块作为样本tokens。 - 右移对齐:
labels = shift_right(tokens);末尾补<eos>或-100(忽略损失)。 - 掩码:构建
attention_mask与因果掩码,保证第 i 位只看见[0..i]。
训练时,模型在每个位置输出 logits(未归一化分数,形状 [batch_size, seq_len, vocab_size]),与 labels(目标 token 索引,形状 [batch_size, seq_len])按位置计算交叉熵并求平均,作为训练损失用于反向传播更新参数。
验证集
不参与梯度更新,用于评估泛化与做模型选择:
- 严格与训练集“文档级去重”,避免数据泄露;按文档稳定哈希划分,典型 90/10 或 95/5。
- 指标:验证 loss / perplexity
- 早停与调参:验证指标无提升触发早停;据此调整学习率、正则、采样配比、上下文长度等超参。
- 选择最佳检查点:保存并选取验证指标最优的 checkpoint 作为后续微调/发布的基座。
损失计算
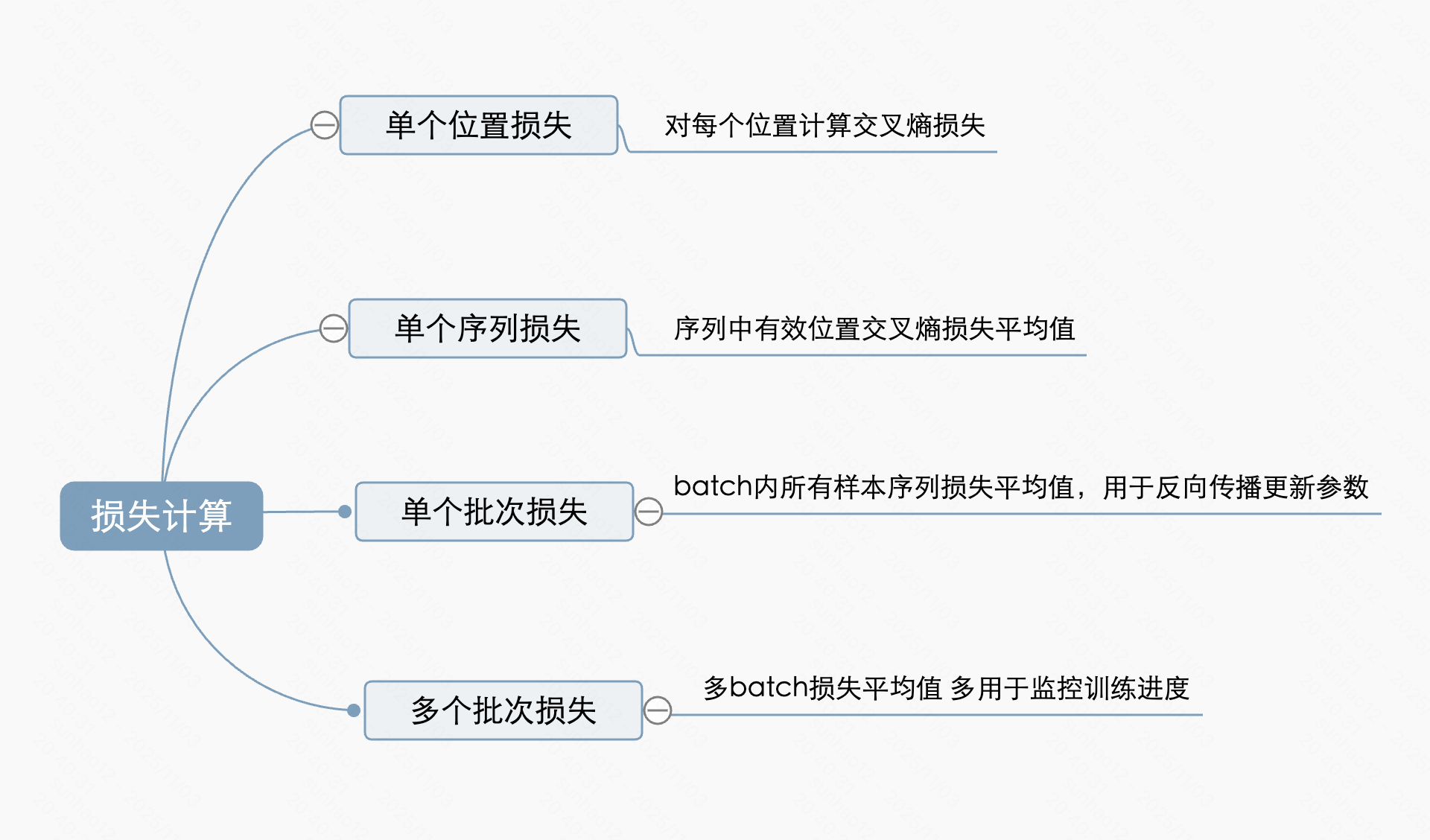
单个位置损失
对于序列中每个位置 i(忽略 labels[i] = -100 的位置),计算 logits[i] 和 labels[i] 的交叉熵损失:
logits[i]形状为[vocab_size],表示该位置对所有词的未归一化分数labels[i]为整数(目标 token 索引)- 损失计算:对
logits[i]应用 softmax 得到概率分布,取labels[i]对应位置的概率,计算负对数 - 含义:模型在该位置预测正确词的概率越高,损失越小
实现训练步骤
大型语言模型的训练是一个迭代优化过程,核心目标是最小化模型预测与真实标签之间的差异。训练通常包含多个训练轮次(Epoch),每个轮次又包含对整个训练集进行分批次(Batch)处理。
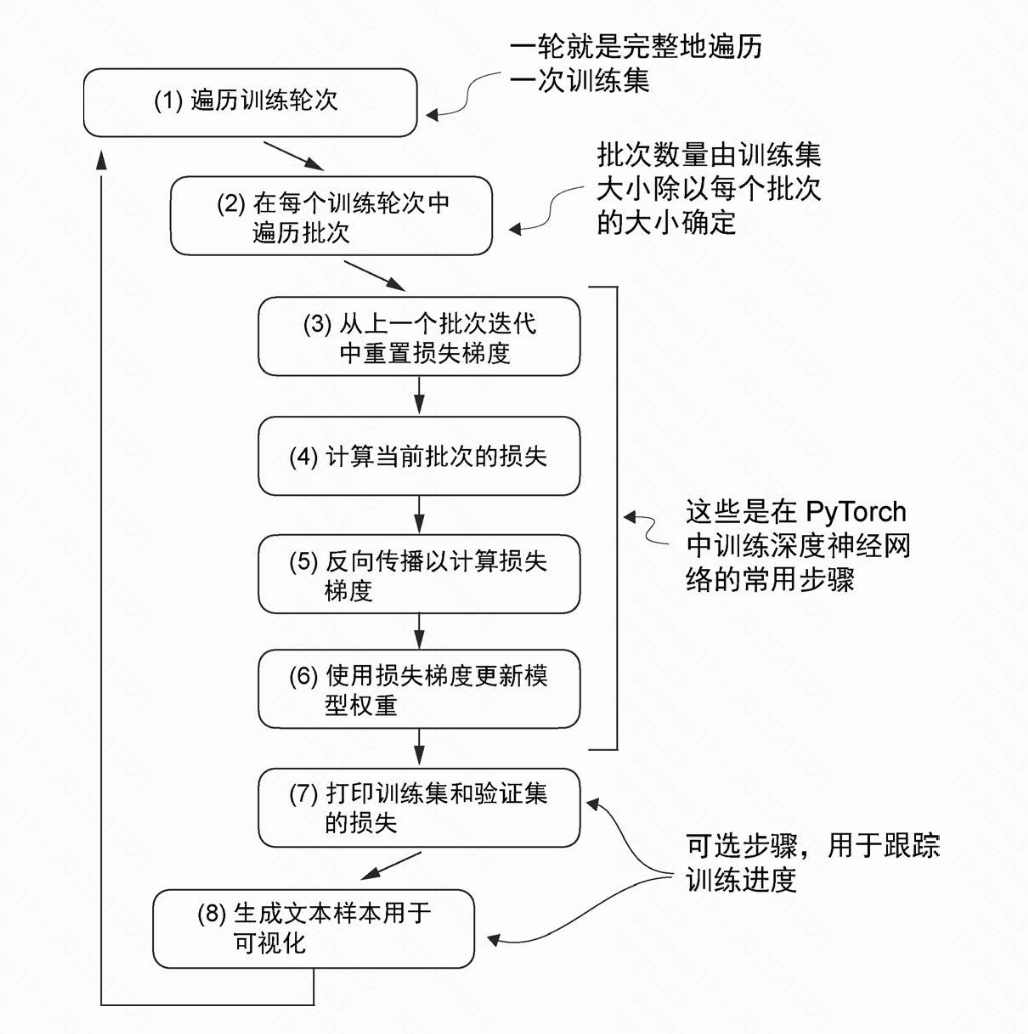
详细训练步骤
1. 遍历训练轮次
- 含义:这是训练的最外层循环。一个“训练轮次”意味着模型会完整地遍历一次整个训练数据集。
- 作用:模型在每个轮次中学习整个数据集的模式,通常需要多个轮次才能收敛。
2. 在每个训练轮次中遍历批次
- 含义:在每个训练轮次内部,训练数据被分割成多个批次。模型逐个批次处理,批次数量 = 训练集总大小 ÷
batch_size。 - 关联:对应文档中“批次(Batch)”的定义,通过并行处理多个样本提高效率和稳定性(见前置概念)。
3. 重置损失梯度
- 含义:处理每个新批次前,需要将优化器中累积的梯度清零,确保当前批次的梯度计算独立,不受之前批次影响。
4. 计算当前批次的损失
- 含义:模型对当前批次进行前向传播,生成预测结果
logits(形状[batch_size, seq_len, vocab_size]),与真实标签labels(形状[batch_size, seq_len])比较,计算批次损失。 - 关联:对应“单个批次损失”计算,即
loss_batch = mean(loss_seq for all sequences in batch)(见损失计算章节)。 - 过程:对每个位置的
logits[i]和labels[i]计算交叉熵,求平均得到loss_batch。
5. 反向传播计算梯度
- 含义:根据步骤 4 的损失值,利用反向传播算法计算损失对模型所有可训练参数的梯度。梯度指示参数调整的方向和幅度。
- 作用:为参数更新提供方向,是模型学习的关键步骤。
6. 更新模型权重
- 含义:优化器(如 Adam、SGD)利用步骤 5 计算的梯度调整模型权重和偏置,使参数朝损失减小的方向移动。
7. 打印训练集和验证集的损失
- 含义:定期评估模型在训练集和独立验证集上的性能,打印相应损失值。
- 关联:对应“多个批次平均(监控指标)”,用于观察训练趋势和评估泛化能力(见损失计算章节)。
- 作用:监控训练进度,判断是否过拟合,决定是否早停或调整超参数。
训练轮次 (Epoch)
└─ 批次 (Batch)
├─ 重置梯度 (zero_grad)
├─ 前向传播 → 计算损失
├─ 反向传播 → 计算梯度
└─ 更新参数 (step)
保存预训练权重
通过保存模型权重,可以方便后续模型的微调和使用。