- Published on
AI探秘-大模型架构解析
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
导航
在自然语言处理(NLP)领域,Transformer 框架的问世标志着深度学习架构的一次革命。从 BERT 到 GPT,这些基于 Transformer 的大模型已经成为推动 AI 技术进步的核心引擎。本文将梳理 Transformer 的三种经典架构(Encoder-only、Encoder-Decoder、Decoder-only),帮助大家深入理解其设计理念与应用场景。
Encoder-only 架构
Encoder-Decoder 架构
Decoder-only 架构
本文梳理每种架构的核心实现,帮助大家对大模型底层架构有更深入的理解。
Encoder-only 架构
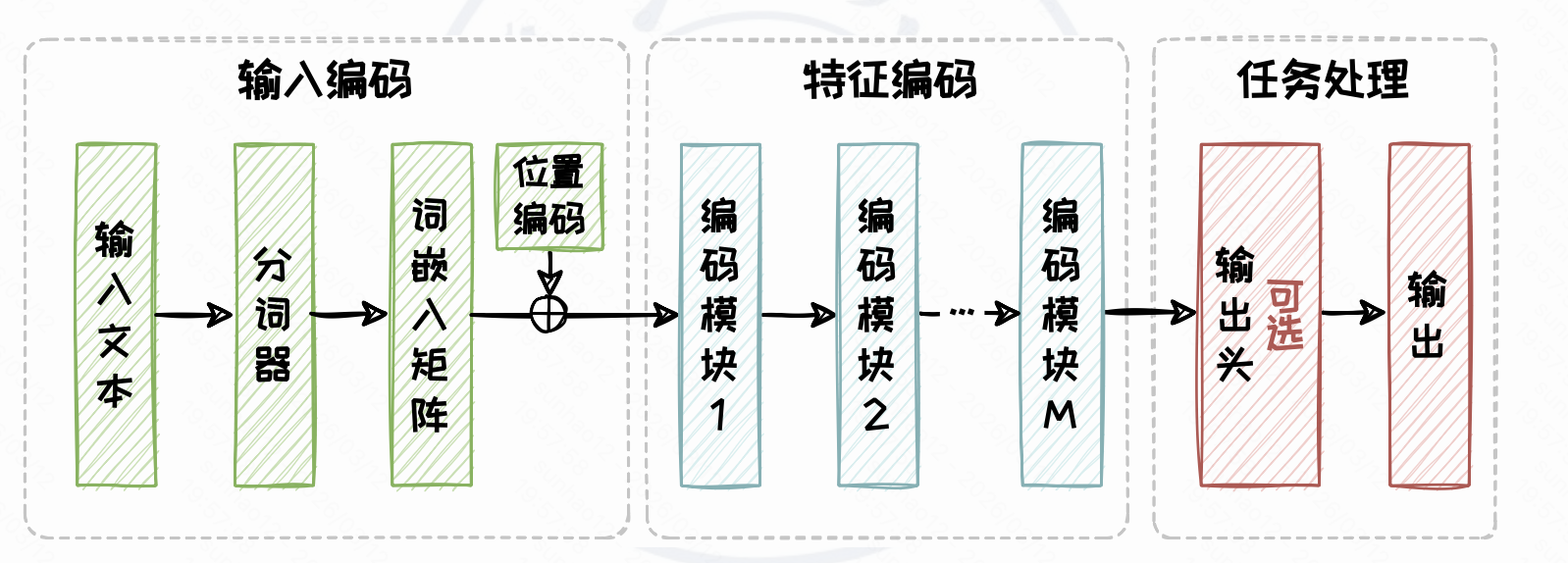
Encoder-only 架构仅选取了 Transformer 中的编码器(Encoder)部分,主要包含以下三个模块:
📥 输入编码
主要包含分词、向量化、添加位置信息。
🔍 特征编码
由多个相同的编码模块堆叠而成,每个编码模块内部包含:
- 自注意力机制
- 全连接前馈模块
🎯 任务处理
任务处理模块根据具体任务设计,例如:
- 分类任务 → 引入专门的分类层
- 其他任务 → 对应定制化输出层
⚖️ 优缺点
✅ 优势
双向注意力机制使每个Token能感知整个输入序列的上下文信息, 因此在需要自然语言理解的任务中表现突出,例如:
- 文本分类(如情感分析、主题分类)
- 命名实体识别(NER)
- 阅读理解 / 问答匹配
❌ 局限
在生成式任务(如文本摘要、翻译)中表现较弱,主要体现在两个方点:
计算成本高:Encoder 不缓存中间状态,每生成一个新 Token, 都需要将原始输入与已生成序列重新打包,从头完整计算一遍注意力, 随序列增长开销显著上升。
生成连贯性差:双向注意力机制在生成时会让已生成的 Token 尝试关注尚未生成的"未来"位置,破坏了生成任务所需的 从左到右的因果顺序,导致输出文本前后缺乏连贯性。
Encoder-Decoder 架构
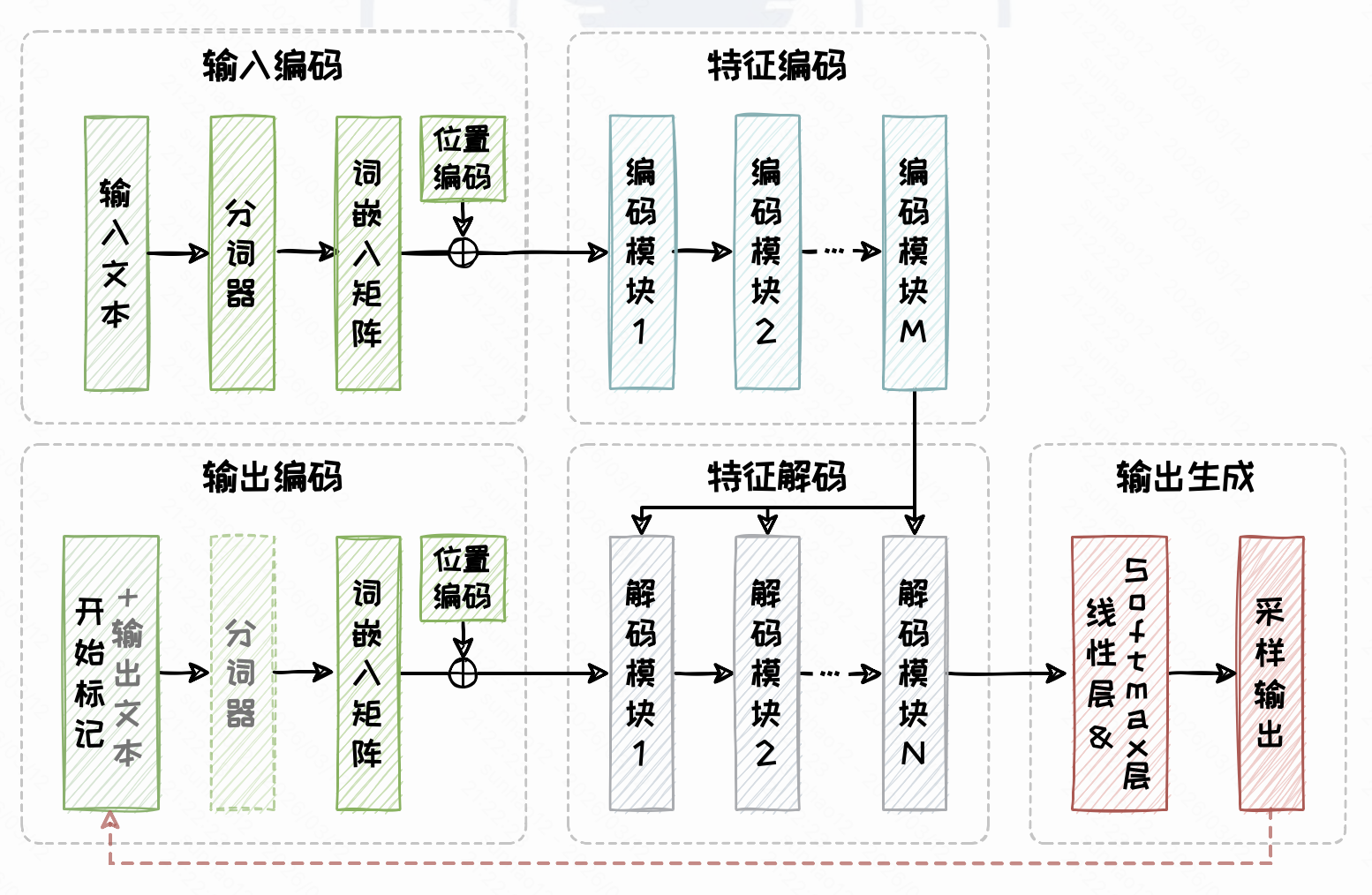
Encoder-Decoder 架构结合了 Transformer 中的**编码器(Encoder)与解码器(Decoder)**部分,主要包含以下模块:
📥 输入编码
与 Encoder-only 架构类似,输入首先经过分词、向量化,并添加位置信息。
🔍 特征编码(Encoder 部分)
由多个相同的编码模块堆叠而成,每个编码模块内部包含:
- 自注意力机制:用于捕捉输入序列的全局依赖关系。
- 全连接前馈模块:对特征进行非线性变换。
🔄 解码(Decoder 部分)
解码器通过多层解码模块逐步生成目标序列,每个解码模块内部包含:
- 掩码自注意力机制:在生成目标序列时,确保解码器仅能关注当前及之前生成的 Token(实现因果注意力)。
- 交叉注意力机制:解码器通过注意力机制与编码器生成的上下文表示交互,理解输入序列的全局信息。
- 全连接前馈模块:用于对解码后的特征进行进一步处理。
🎯 任务处理
任务处理模块根据具体任务设计,例如:
- 机器翻译:将源语言序列编码为上下文表示,再解码为目标语言序列。
- 文本摘要:将长文本编码为紧凑的上下文表示,再解码为摘要。
⚖️ 优缺点
✅ 优势
Encoder-Decoder 架构在各种复杂的有条件生成任务中表现出色,原因包括:
- 双向上下文理解:编码器通过双向注意力机制,捕捉输入序列的全局信息。
- 因果生成能力:解码器通过掩码自注意力机制,确保生成序列遵循从左到右的时间顺序。
- 灵活性强:适用于多种需要输入输出序列对齐的任务,例如:
- 机器翻译
- 文本摘要
- 图像描述生成
❌ 局限
尽管 Encoder-Decoder 架构功能强大,但也有一些局限性:
- 计算成本高:需要同时计算编码器和解码器的注意力机制,计算开销较大。
- 训练复杂性:需要处理输入和输出序列的对齐问题,训练过程相对复杂。
Decoder-only 架构
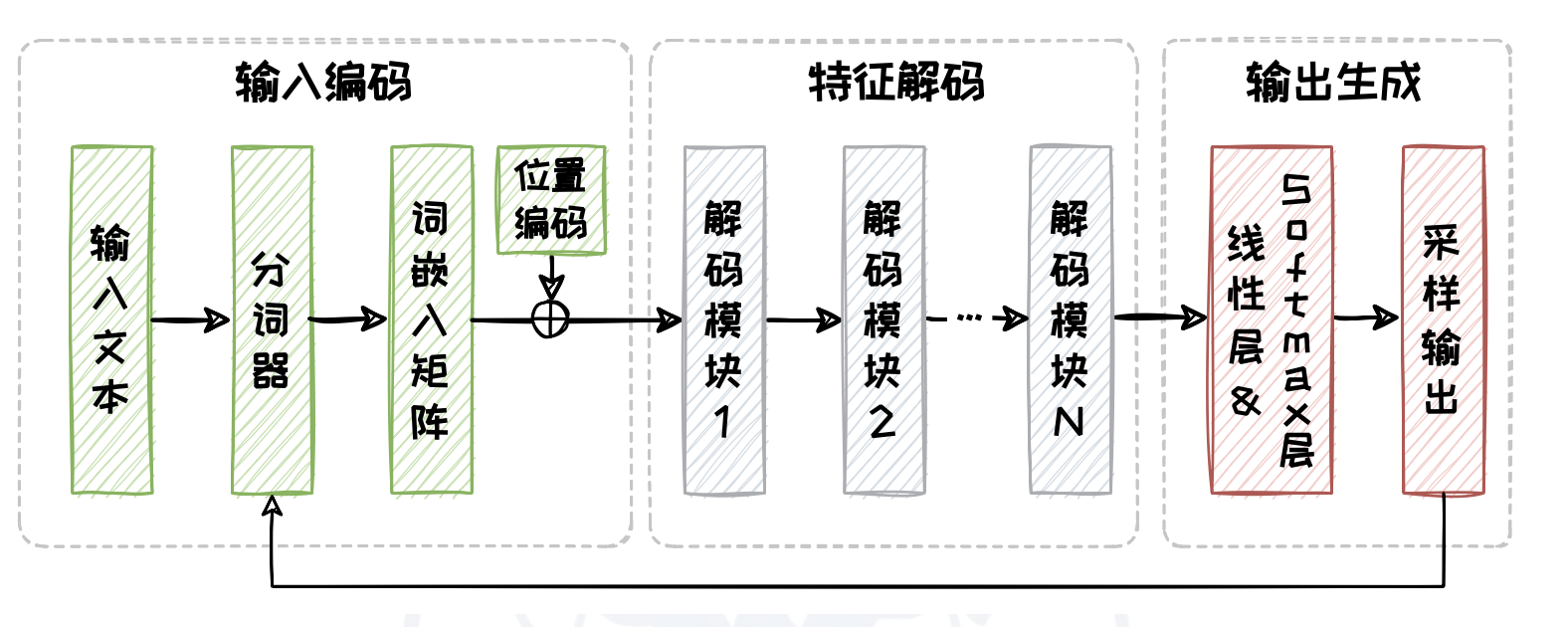
Decoder-only 架构仅选取了 Transformer 中的解码器(Decoder)部分,主要包含以下模块:
📥 输入编码
输入序列首先经过分词、向量化,并添加位置信息。
🔄 解码(Decoder 部分)
解码器由多个相同的解码模块堆叠而成,每个解码模块内部包含:
- 掩码自注意力机制:确保解码器在生成目标序列时,仅能关注当前及之前生成的 Token,遵循从左到右的因果顺序。
- 全连接前馈模块:对特征进行进一步线性变换和非线性处理。
🎯 任务处理
任务处理模块根据具体任务设计,例如:
- 文本生成:直接生成目标序列,例如对话生成、文章续写。
- 代码生成:生成代码片段或自动补全代码。
- 语言建模:预测下一个 Token 的概率分布。
⚖️ 优缺点
✅ 优势
Decoder-only 架构在无条件文本生成任务中表现优异,原因包括:
- 高效生成:可以逐步生成目标序列,每一步生成时只需关注已生成的部分,避免了重复计算。
- 因果顺序:通过掩码自注意力机制,确保生成序列遵循从左到右的时间顺序,生成结果更连贯。
- 专注生成:专门设计用于生成任务,适合大规模预训练后在多种生成任务上进行微调,例如:
- 对话系统
- 代码生成
- 文章续写
❌ 局限
尽管 Decoder-only 架构在生成任务中表现突出,但也存在一些不足:
- 缺乏全局上下文:由于采用单向注意力机制(从左到右),在处理需要全局语义理解的任务时表现欠佳,例如文本分类、阅读理解等。
- 依赖上下文长度:生成时需要保存所有已生成的 Token 上下文,序列长度过长时可能导致内存开销较大。