- Published on
AI探秘-理解模型采样
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
大模型在文本生成时,模型在每个位置输出一个词元的概率分布,根据这个概率分布选择下一个词元的过程称为采样(Sampling)。不同的采样策略会影响生成文本的多样性和质量。 本文介绍大模型中常用的采样策略。
概率最大化方法
概率最大化的要点在于模型生成的整段文本概率最大,这在搜索空间上很大,是典型的NP-Hard问题. 通常采用启发式的搜索方法来解决这种问题, 常见的有:
- 贪婪搜索(Greedy Search)
- 波束搜索(Beam Search)
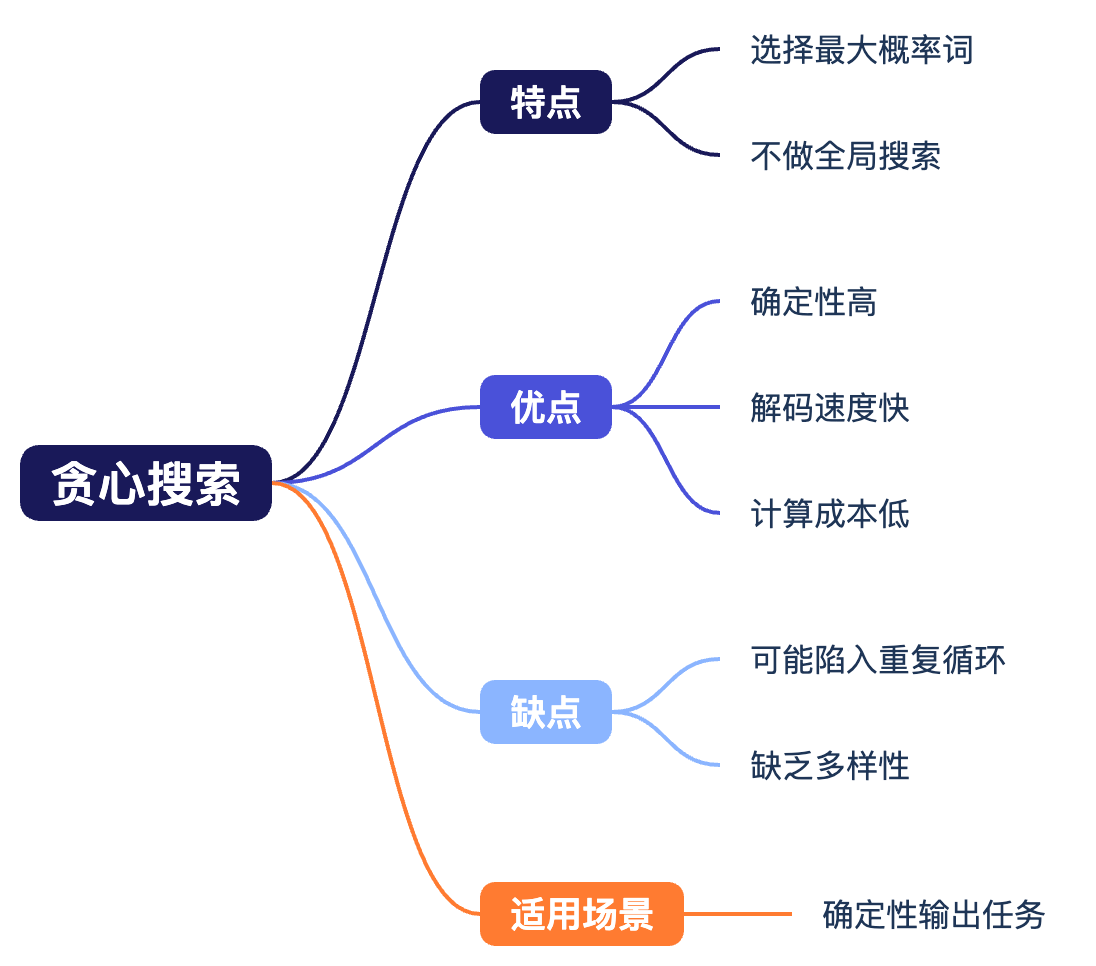
贪婪搜索(Greedy Search)
贪婪搜索是最简单的概率最大化方法,每一步都选择当前概率最大的词元作为输出,不考虑后续词元的影响.
波束搜索(Beam Search)
波束搜索在每一步保留多个候选词元,通过扩展这些候选词元生成多个候选序列,最终选择概率最高的序列作为输出. 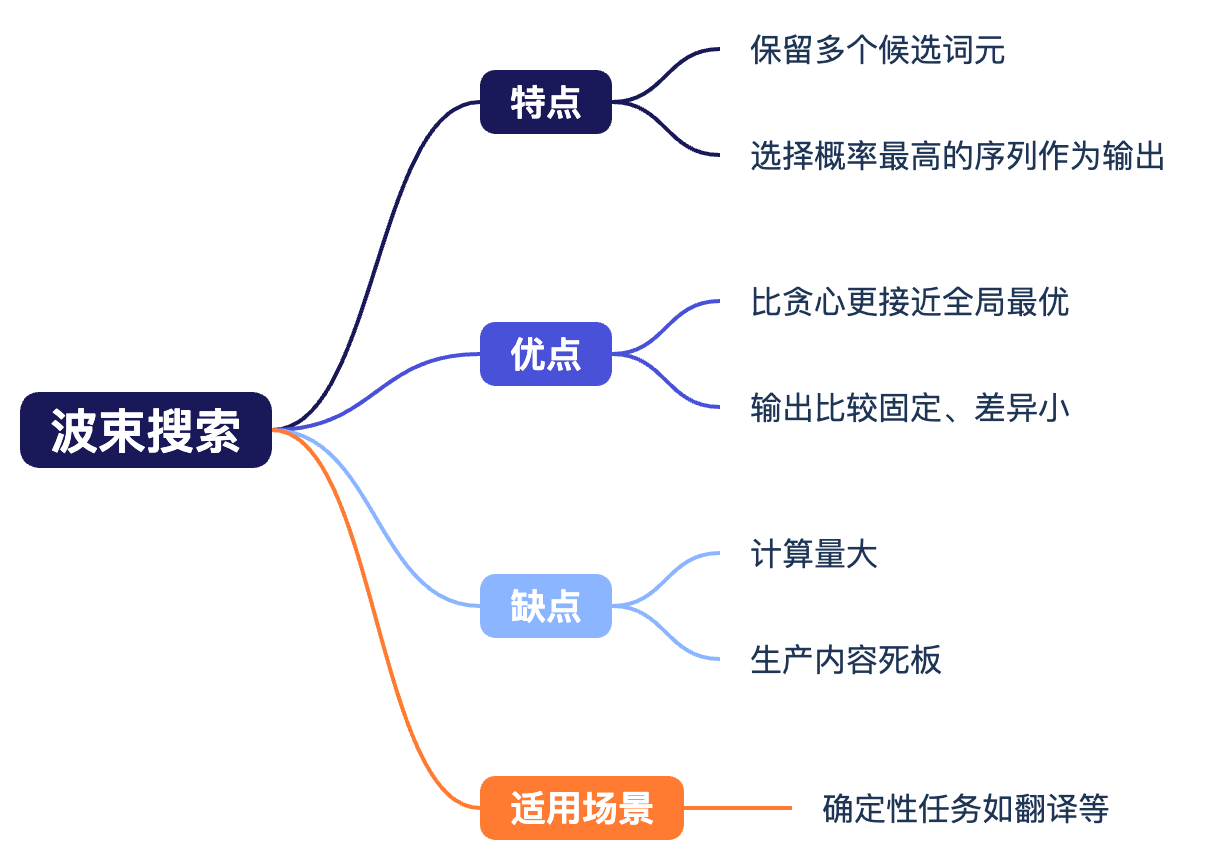
随机采样方法
随机采样方法通过引入随机性来增加生成文本的多样性,在每轮预测时,先选出一组可能性高的候选词,然后根据它们的概率分布进行采样。 常见的有:
- Top-k 采样
- Top-p 采样
- 温度机制(Temperature)
Top-k 采样
Top-k 采样是指在每一步预测时,只考虑概率最高的k个词元作为本轮的候选词集合 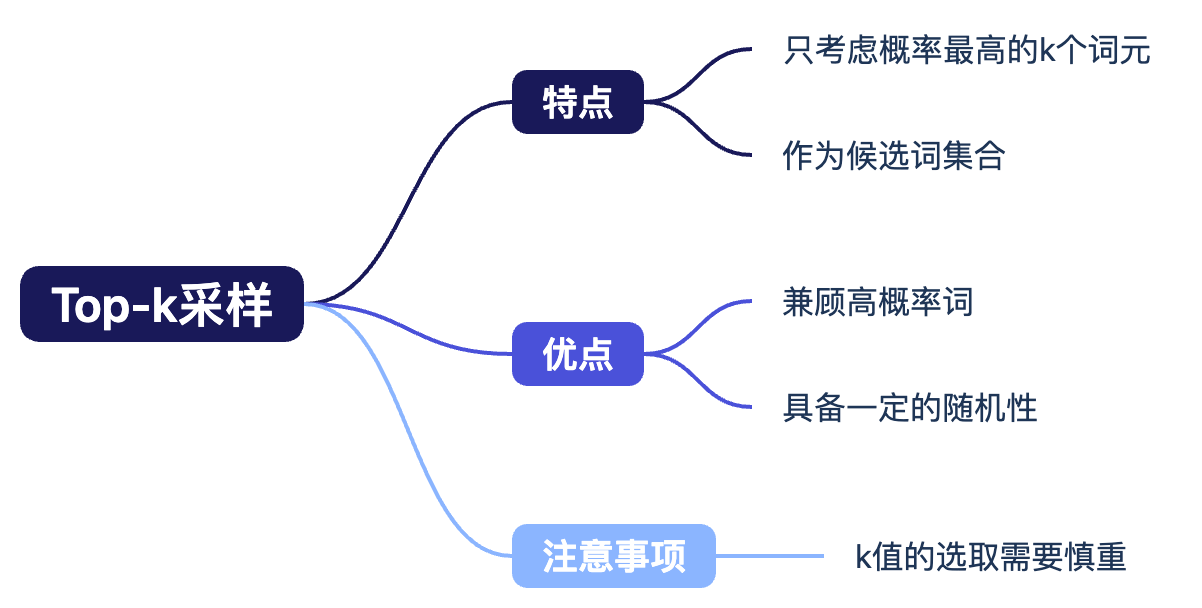
Top-p 采样
Top-p 采样(又称核采样)是指在每一步预测时,选择累计概率达到阈值p的最小词元集合作为候选词集合 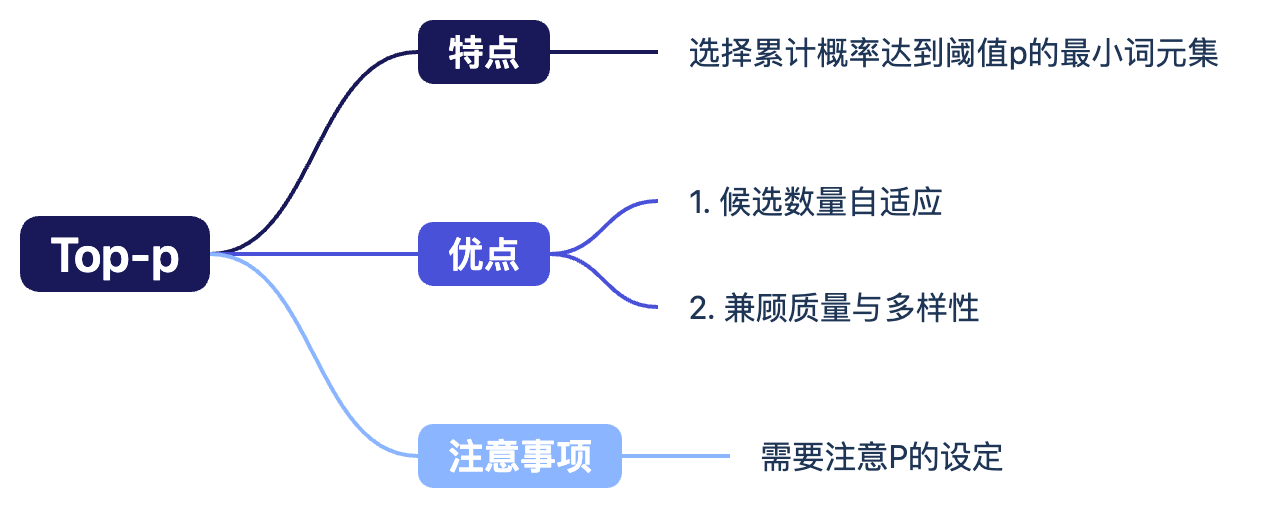
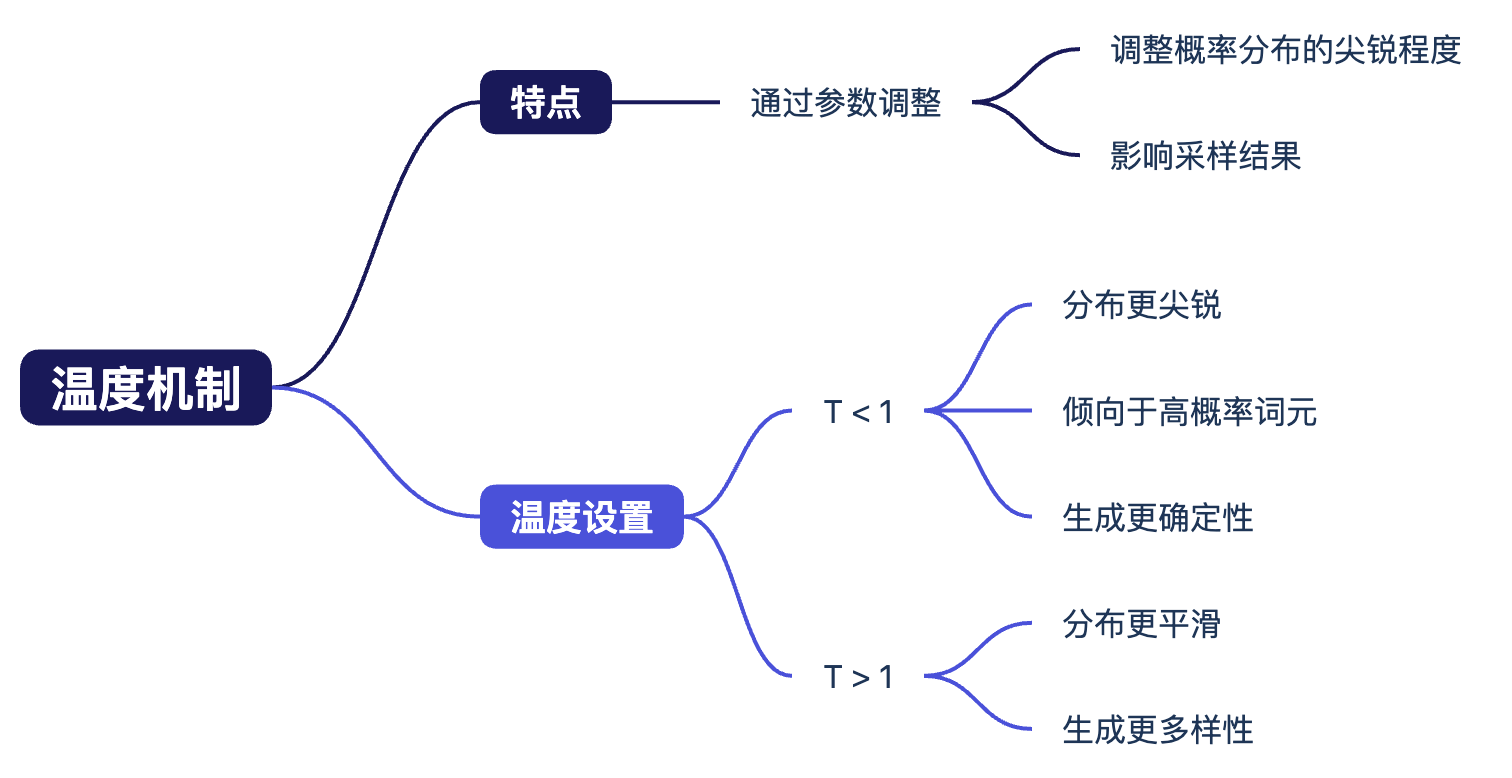
温度机制(Temperature)
温度机制通过调整概率分布的平滑度来控制生成文本的多样性。