- Published on
AI探秘-大模型:我的记忆不止5秒
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
导航
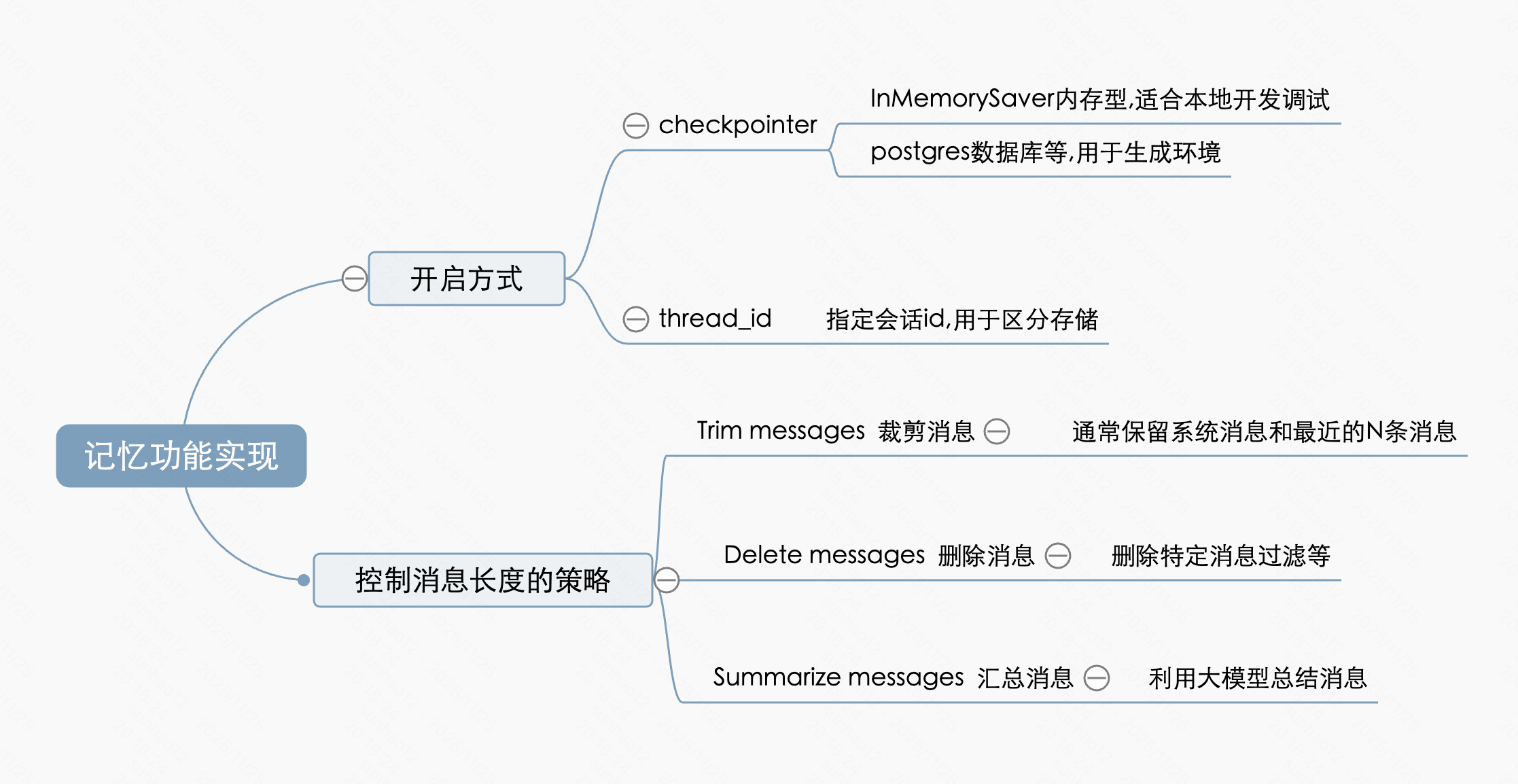
在AI探秘-LangChain使用不完全指南中介绍了LangChain核心组件的基本使用方式.通过对 基本组件的了解我们知道如何简单构建一个agent.但是我们对构建大模型的一些交互细节还不明确.AI探秘系列会继续在这个方向进行探索,本文将了解在大模型中是如何实现记忆的. 在大语言模型的上下文窗口有限,对话轮数越多,越容易丢失关键信息.短期记忆(Short-term Memory)的核心是把当前对话历史保存到一份状态里,在下一次调用模型之前再读出来,从而让Agent拥有连贯的对话上下文. 在LangChain中,这份状态由AgentState管理,并通过checkpointer持久化.
如何启用短期记忆
在创建Agent时指定checkpointer,LangChain就会在状态里记录每一次的消息流. 本地开发时可以使用 anggraph.checkpoint.memory.InMemorySaver将对话状态保存在内存中,方便快速调试和实验。 线上环境则推荐langgraph-checkpoint-postgres等数据库后端,持久化存储对话状态.
控制消息长度的常见策略
默认的AgentState只维护messages,可以通过扩展AgentState和添加中间件来实现对消息的处理逻辑.启用短期记忆后,历史记录可能超出上下文窗口,需要配合裁剪策略:
| 策略 | 说明 |
|---|---|
| Trim messages | 通过 @before_model 中间件统计消息数量/Token 并保留最近的若干轮,必要时可以先固定保留第一条系统信息再拼接最近的 N 条对话。 |
| Delete messages | 借助 RemoveMessage 直接从状态里删除某些消息,常用场景包括清理敏感信息或过期内容。 |
| Summarize messages | 将较早的多轮对话压缩成摘要再放回状态,用更少的 Token 保留关键信息。 |
| Custom strategies | 例如按角色过滤消息等,可以根据业务需求自定义更多裁剪策略。 |
压缩消息
总结消息
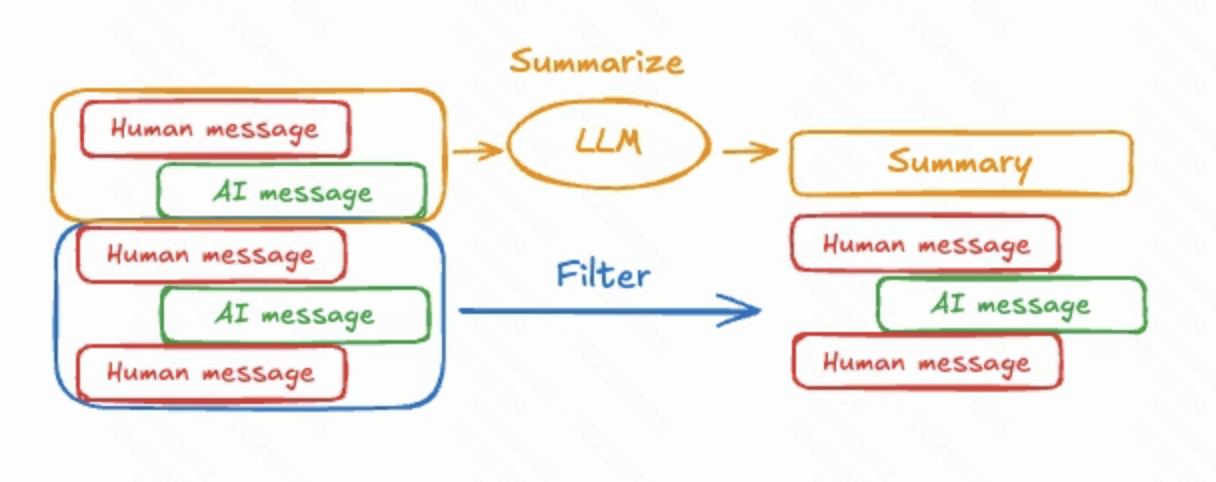
短期记忆并不是无限制地存放所有内容,而是通过合理的持久化与裁剪策略,把最重要的信息留在Agent的“脑海”里.这也是LangChain在构建工业级Agent时的一项关键能力.
参考
LangChain Short-term Memory 官方文档.