- Published on
AI探秘-大模型原理
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
LLM
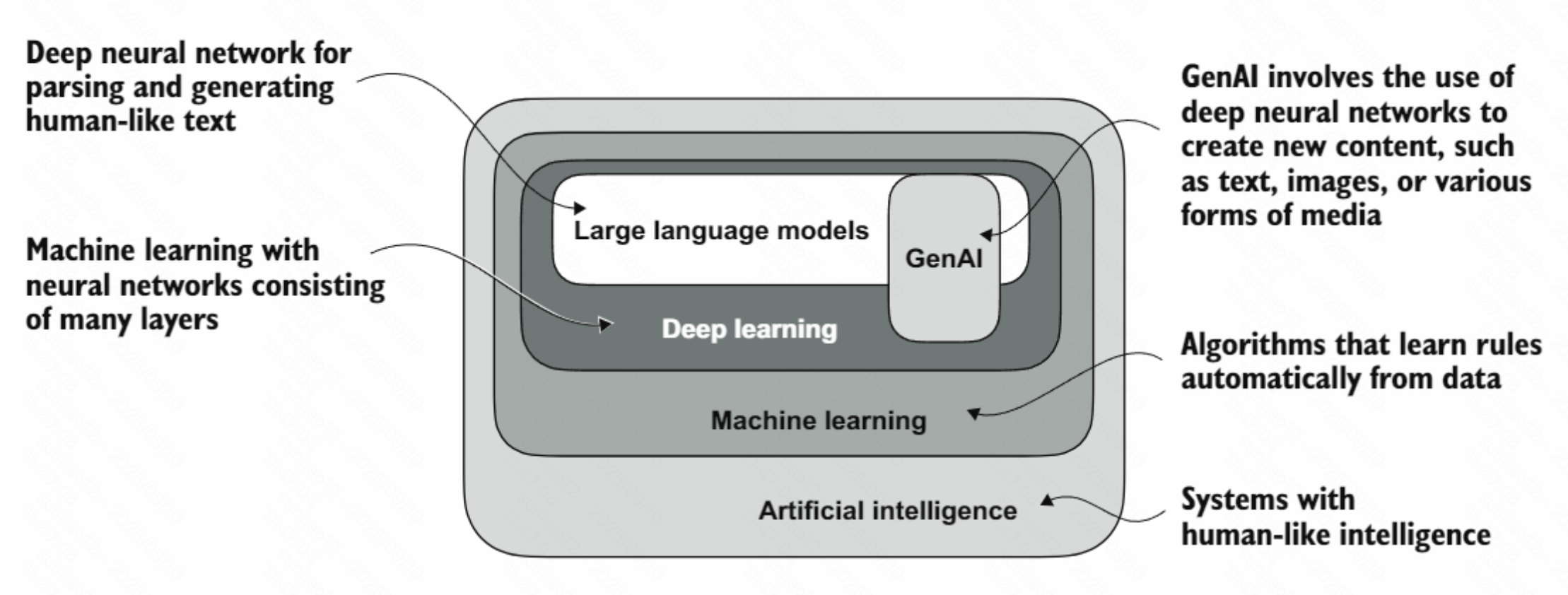 LLM(Large Language Model)是一种神经网络,具有理解、生成和回应类似人类的文本。大模型的大主要因为:
LLM(Large Language Model)是一种神经网络,具有理解、生成和回应类似人类的文本。大模型的大主要因为:- 模型的参数规模
- 训练使用的海量数据集
核心术语
- 预训练 (Pre-training): 用大规模、多样化的数据集训练一个大模型,让它学到通用表征与基础能力得到基座模型
- 微调 (Fine-tuning): 在已有预训练大模型的基础上,用较小的任务/领域数据继续训练得到微调模型
- 自监督学习 (Self-supervised Learning): 不依赖人工标注,利用数据自身构造"伪标签/预任务"来训练模型,从而学到通用表征与结构
- 指令微调 (Instruction Tuning): 让大模型学会"听懂并遵循人类指令"的通用对话/任务能力。在指令微调中,标记数据集由指令和答案对组成
- 分类微调 (Classification Fine-tuning): 让模型在特定分类任务上输出离散标签。标记数据集由文本及其相关类别标签组成
- 自注意力机制 (Self-Attention): 让序列中每个位置都能直接"关注"到序列中所有其他位置,计算它们之间的相关性权重,从而捕捉长距离依赖关系。自注意力让模型能够"同时看到"整个序列,并学会哪些部分之间最相关,这是 Transformer 和大模型强大的核心机制
- 嵌入向量 (Embedding Vectors): 将离散的符号(如单词、字符、句子)转换为连续的高维数值向量的技术。这些向量能够捕捉符号的语义信息和上下文关系
- GPT (Generative Pre-trained Transformer): 生成式预训练Transformer
Transformer架构
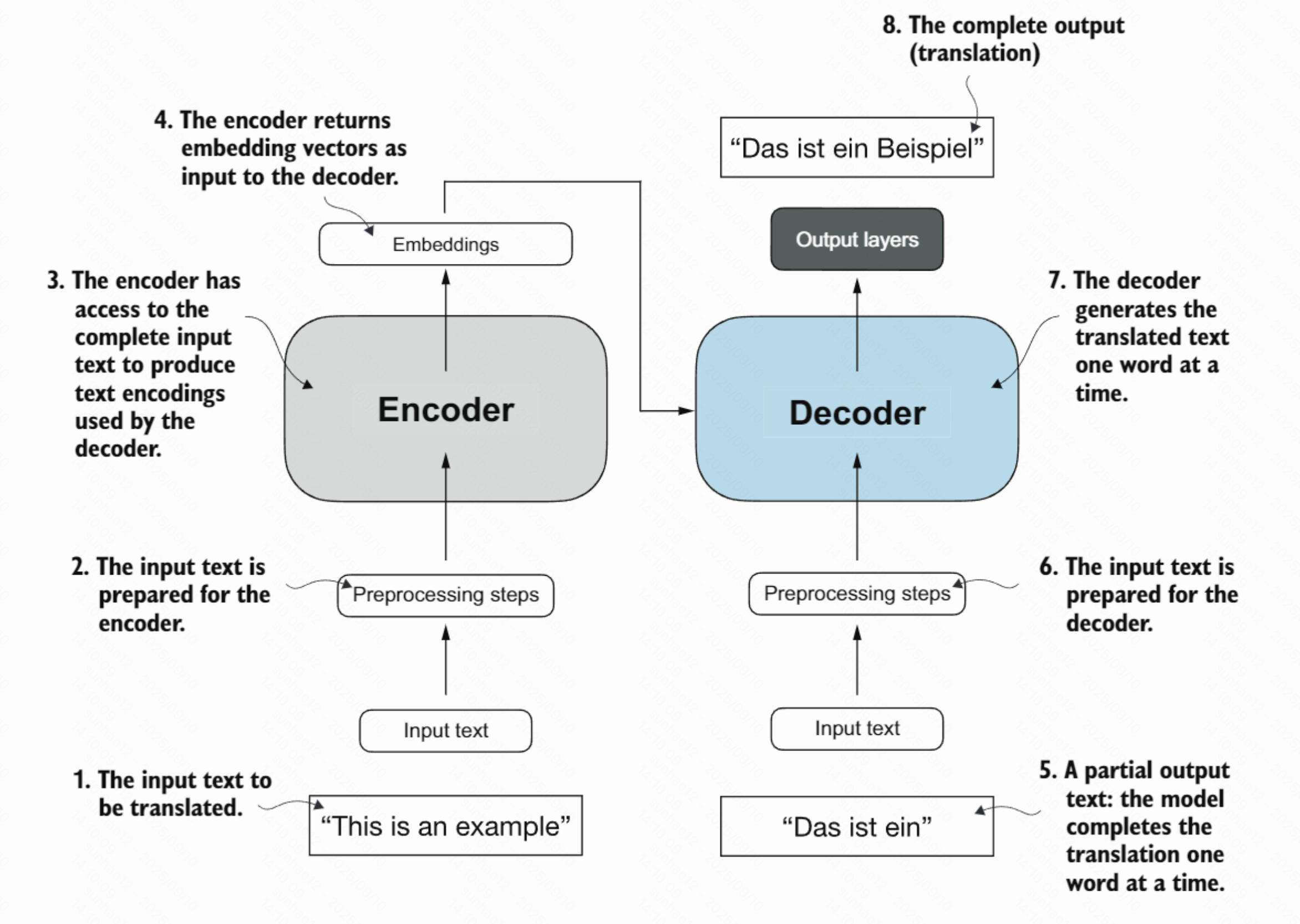
核心组件
- 编码器(Encoder): 负责理解源语言的输入文本,将其转换为嵌入向量
- 解码器(Decoder): 利用编码器的输出逐步生成目标语言的翻译
工作步骤
1. 输入文本准备
- 用户输入待翻译的文本:"This is an example"
- 文本经过预处理:分词、添加特殊标记、转换为数字ID
2. 编码器处理
- 编码器接收预处理后的完整输入文本
- 为每个位置生成上下文表示(隐状态序列),保留位置信息与全局依赖
- 生成与上下文相关的表示(非仅词嵌入)
3. 上下文传递
- 编码器输出上下文表示(隐状态序列/注意力键值)供解码器查询
- 这些表示是输入文本的密集语义表征
- 解码器通过注意力从这些表示中按需取用相关信息
4. 逐步生成翻译
- 解码器一次生成一个词,例如首先生成:"Das ist ein"
- 将已生成的部分翻译作为输入,结合编码器的上下文信息
- 预测下一个最有可能的词
5. 输出层处理
- 通过输出层(全连接层和softmax激活函数)
- 生成完整的翻译结果:"Das ist ein Beispiel"
GPT(Generative Pre-trained Transformer)
GPT与传统Transformer区别
传统 Transformer(编码器-解码器)
- 编码器:双向自注意力,读取完整输入并产出上下文表示
- 解码器:带因果掩码的注意力,结合编码器的表示逐步生成输出
- 常用于翻译等序列到序列任务
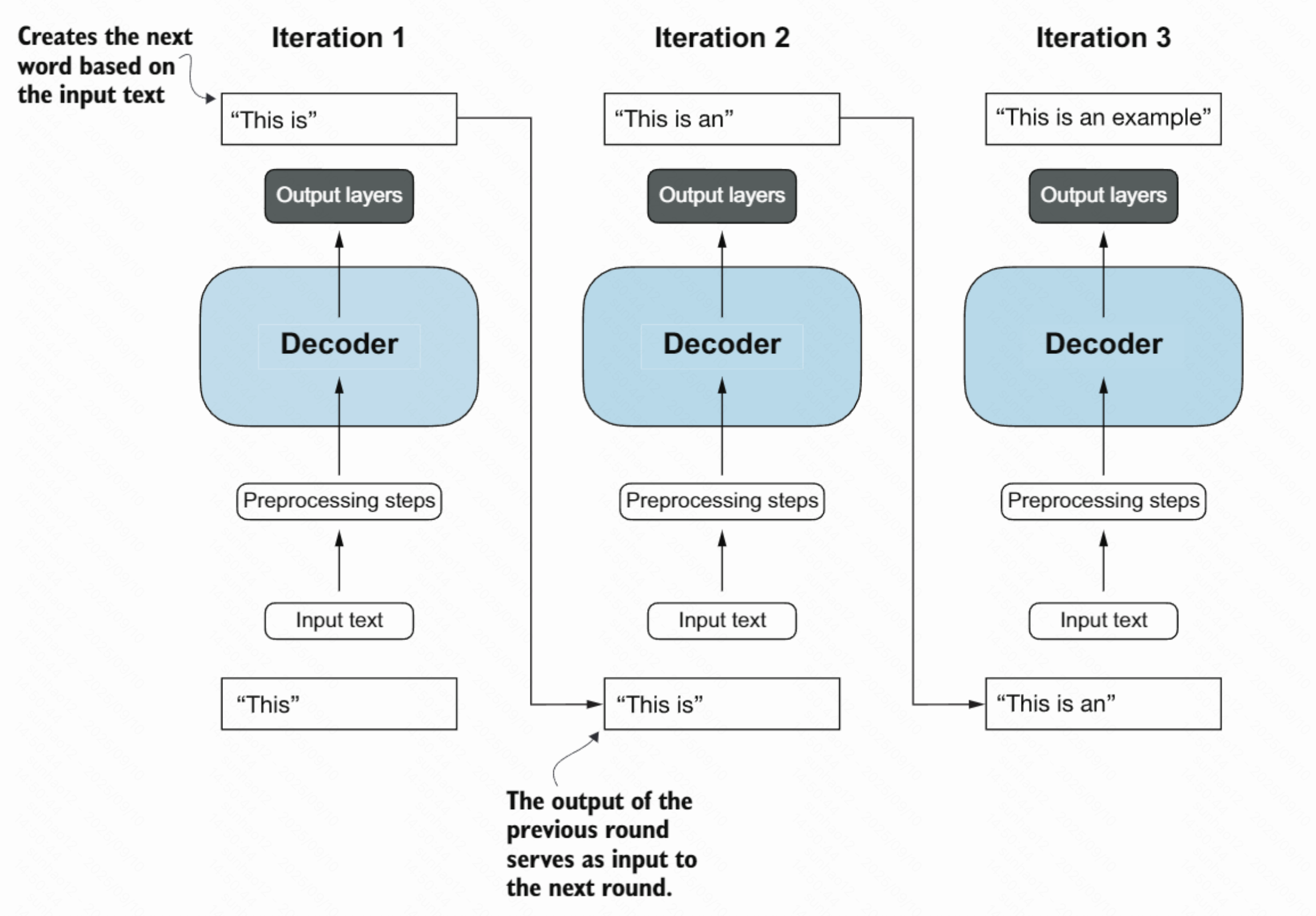
GPT(仅解码器)
- 结构:仅解码器堆叠,使用因果注意力(只看当前位置之前的token)
- 流程:
输入文本 → 解码器 → 输出文本 - 能力:通过大规模预训练获得强理解能力,但没有单独的编码器模块
- 侧重:自回归生成,更适合生成式任务
GPT 的工作原理
训练阶段
- 预训练: 在大规模文本上学习语言模式
- 自监督学习: 预测下一个词
- 学习通用表征: 获得语言理解能力
生成阶段
- 接收输入: 用户提供的提示文本
- 自回归生成: 逐个预测下一个词
- 输出结果: 生成完整的回复