- Published on
AI探秘-构建大模型数据准备流程
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
相关概念
- Byte Pair Encoding(BPE,字节对编码):常用的子词分词算法,用于把文本切成更稳定的子词 token,兼顾未登录词处理与词表大小控制。
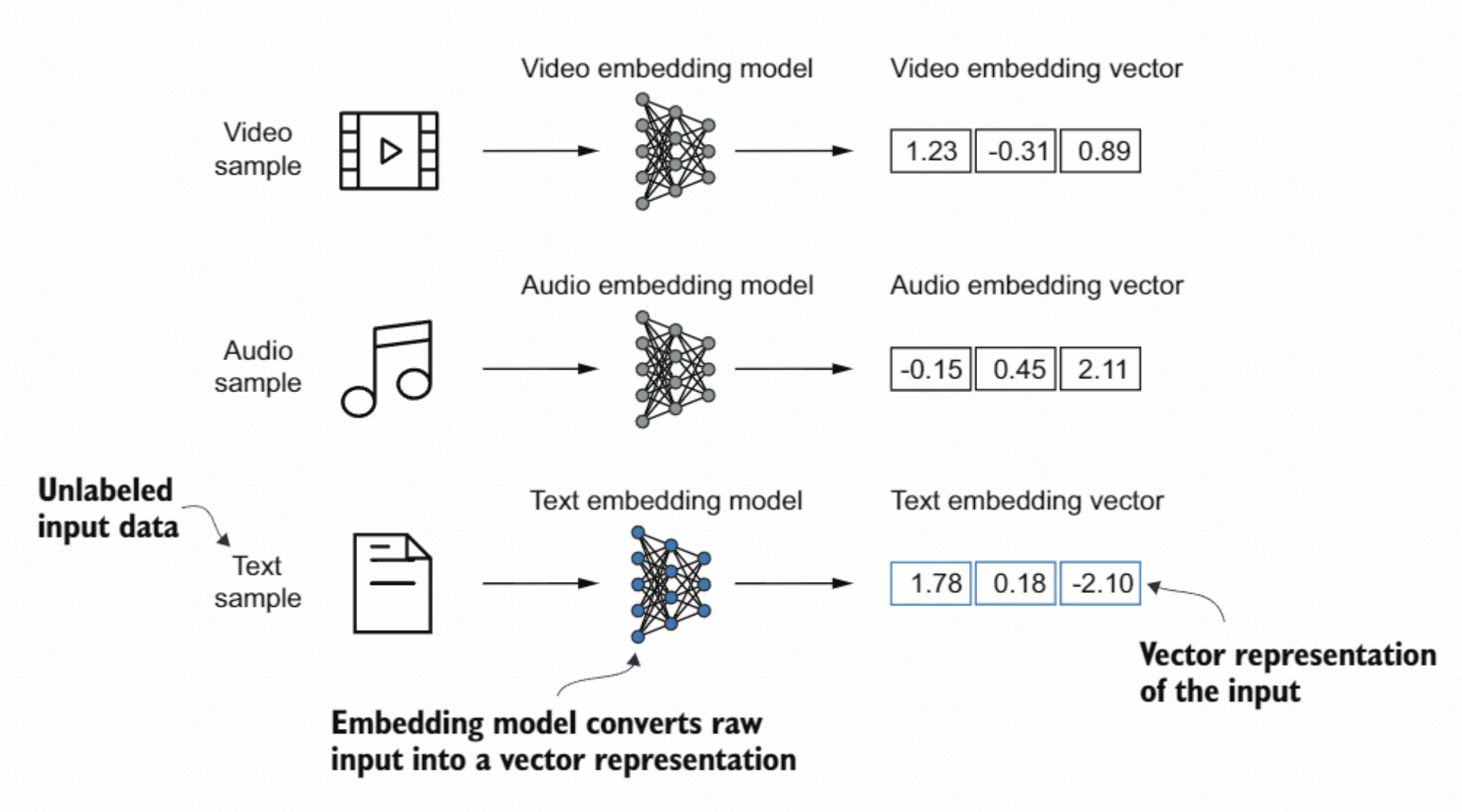
- Embedding(嵌入):把离散对象映射到稠密向量空间的过程或机制。主要目的是把非数值型数据转换成神经网络可处理的数值表示。
- Embedding model(嵌入模型):专门将输入(文本/图像/音频/ID 等)映射为稠密向量的模型,用于语义相似度、检索、聚类与下游任务特征输入。
- 词表(vocabulary):token ↔ id 的映射表,用于编码(token→id)与解码(id→token),通常包含特殊符号(如
<eos>、[PAD]、[UNK])。
构建大模型步骤
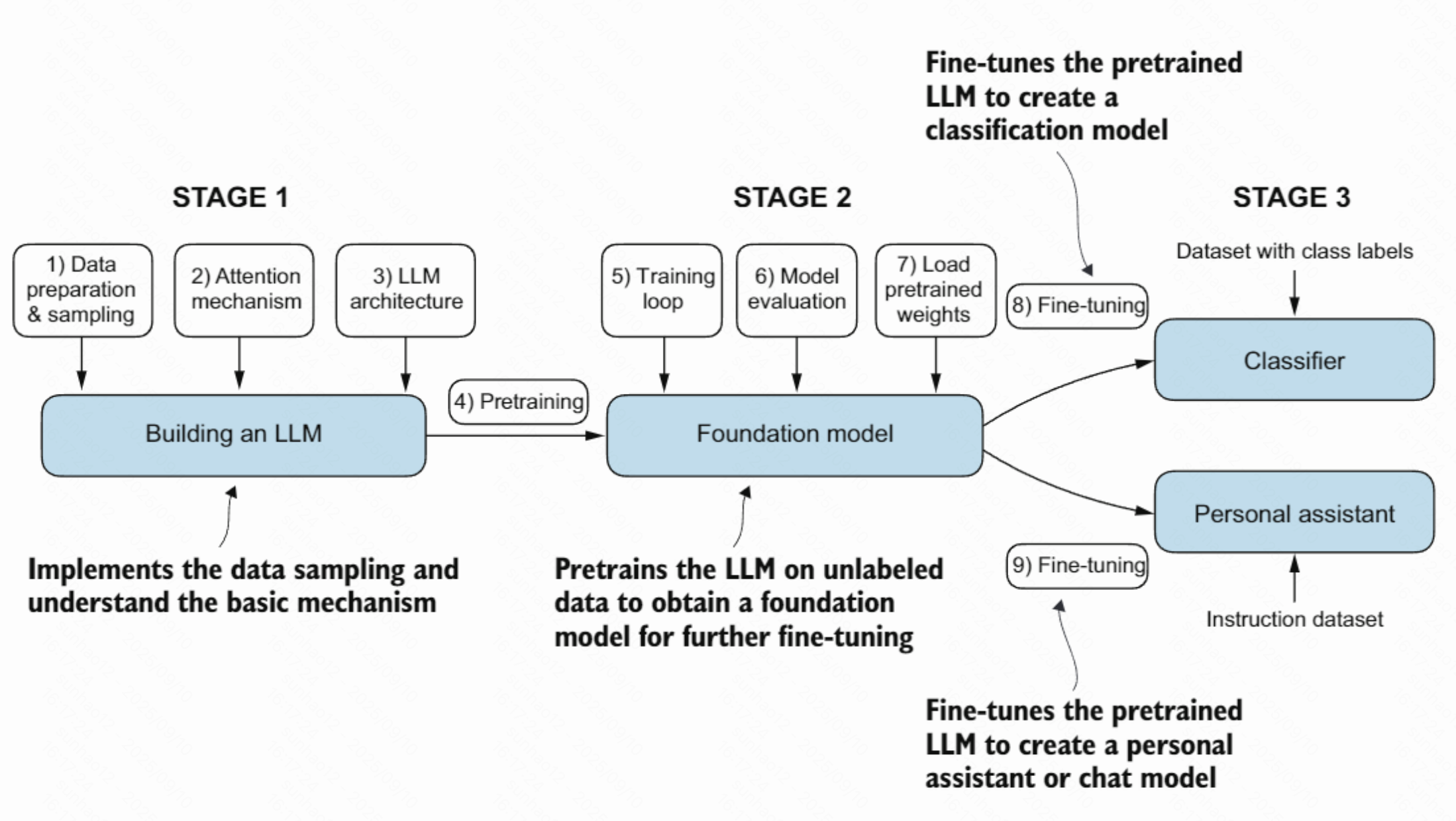
- 实现 LLM 的架构并完成数据准备流程。
- 预训练 LLM,得到基座(基础)模型。
- 在基座模型上进行微调,使其成为个人助手或文本分类器等下游任务模型。
数据准备流程
分词(Tokenized text)
- 将原始文本按规则切分为更小的单位(token),如词、子词、字符或标点。
ID 化与样本构造
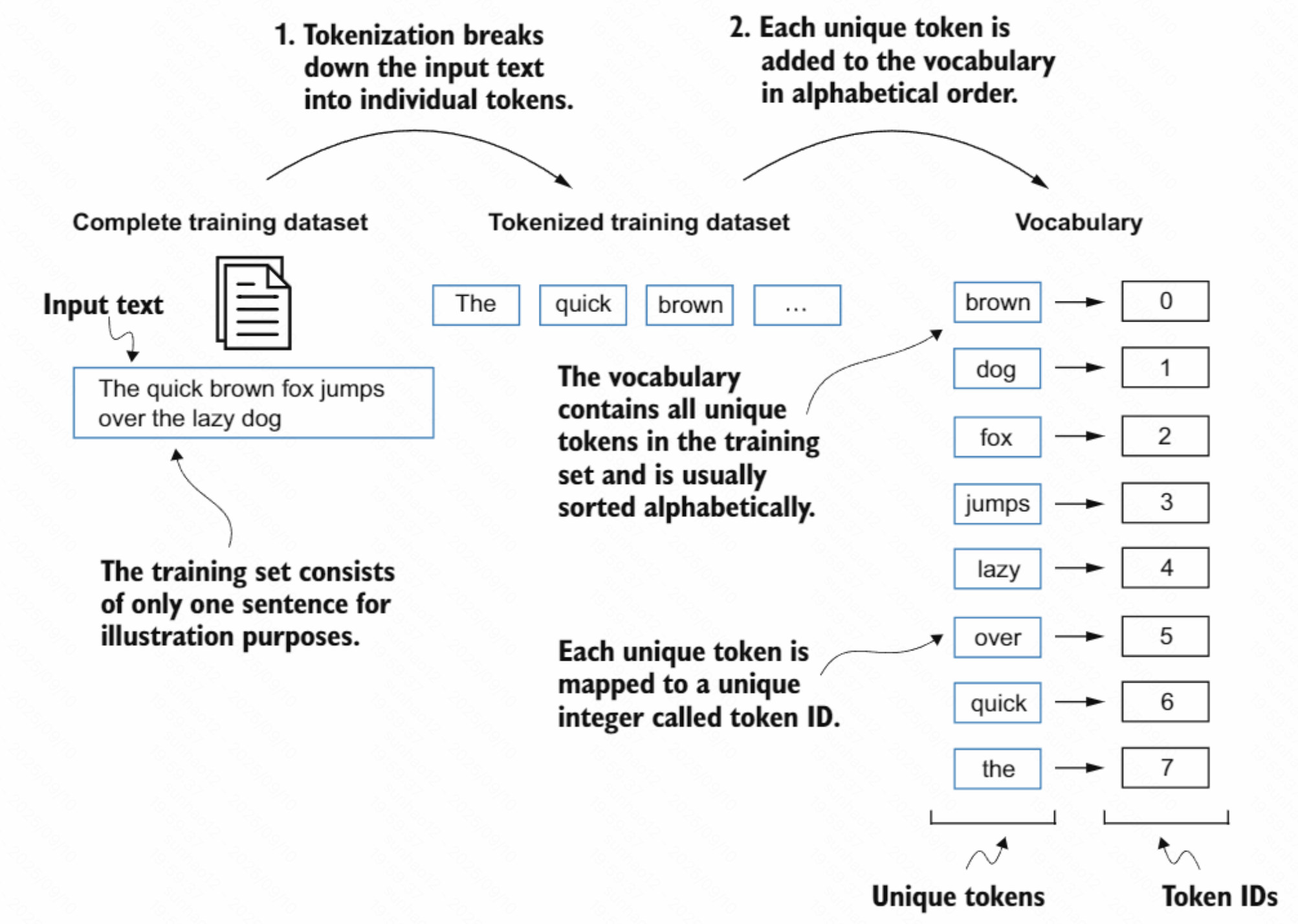
将获得的 token 结合 vocabulary(词表/词汇表)转换为 Token IDs。
生成词表:
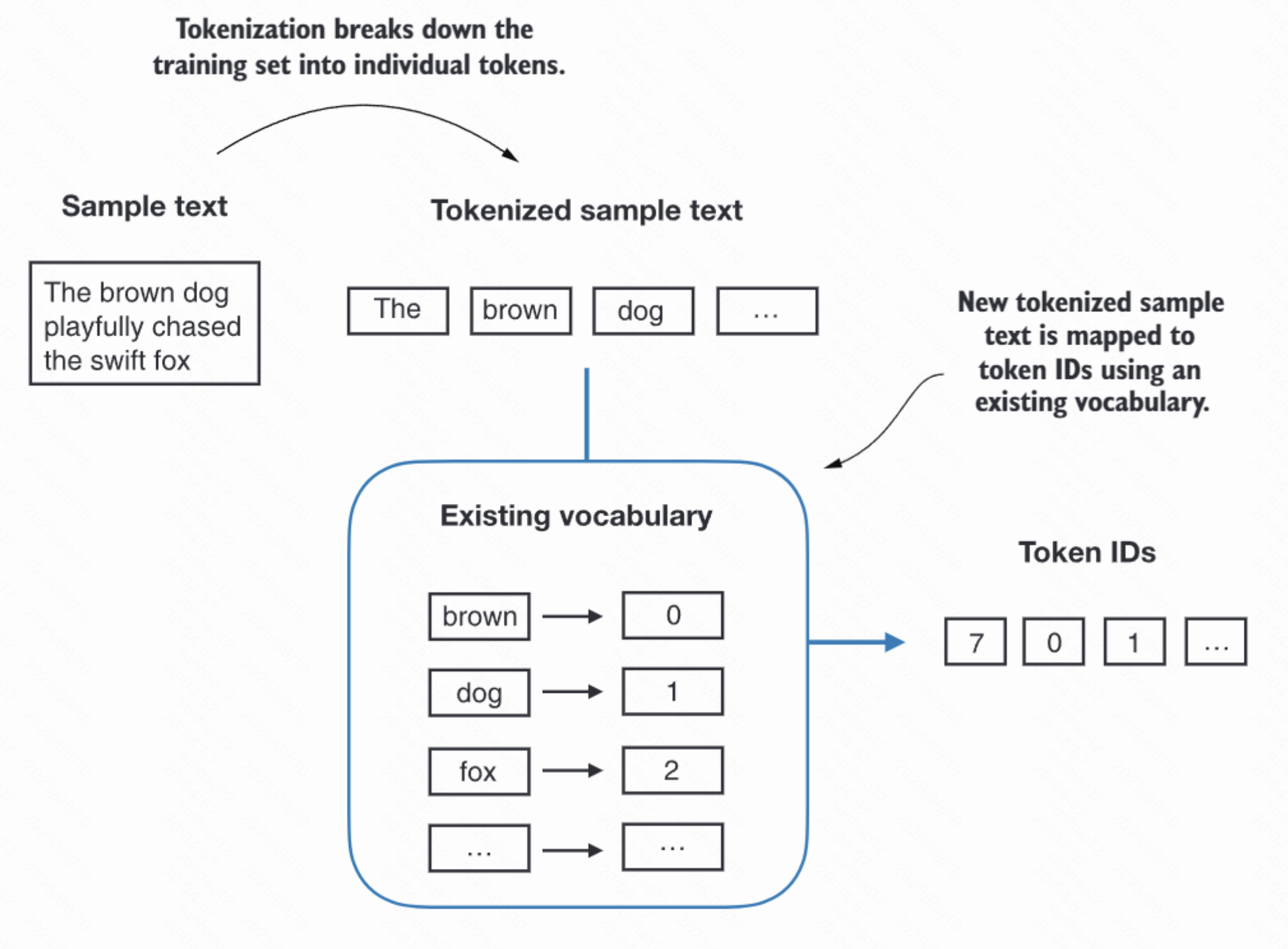
生成 Token ID:
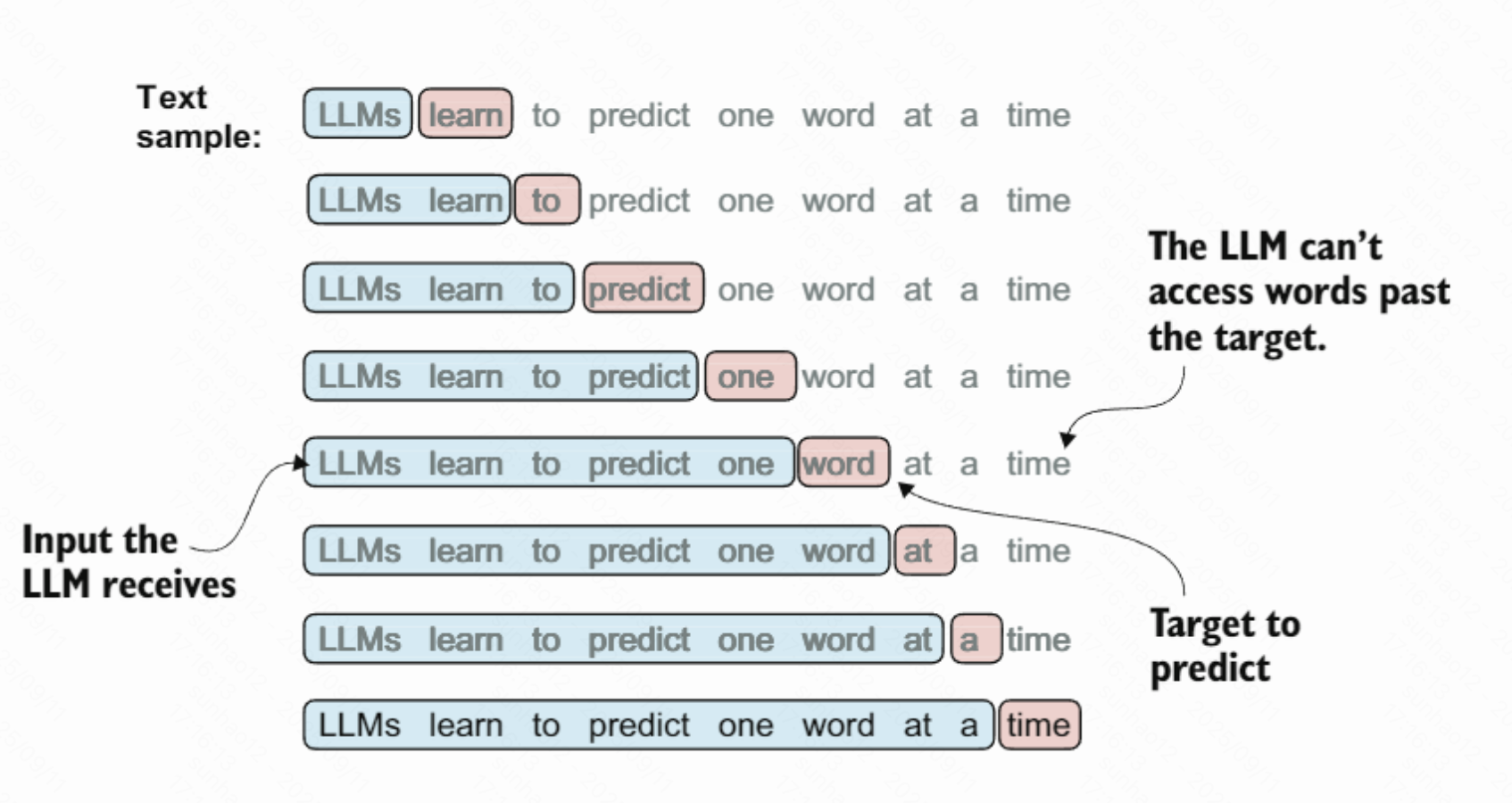
构造输入–目标对(input–target pairs)用于训练:
向量化(Embeddings)
- Token embeddings(词元嵌入):将文本中的每个词元(token)转换为一个固定维度的稠密向量。每个 token 的 ID(索引值)通过查找嵌入矩阵(embedding matrix)映射到一个d维的向量空间表达内容语义。
- Positional embeddings(位置嵌入):由于 Transformer 模型的自注意力机制(Self-Attention)对序列中的位置不敏感,因此需要额外的位置信息来帮助模型区分词元的顺序。Positional embeddings 是为序列中每个位置生成的固定维度向量,表示该位置的位置信息。
- 合成输入向量(Input embeddings):通常为 Token embeddings 与 Positional embeddings 逐元素相加后的结果,输入到模型中。