- Published on
AI探秘-如何本地部署大模型
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
在之前的文章中了解了大模型流式输出是如何实现的和 工作流工具n8n初体验,这篇文章继续深入大模型探秘系列,了解如何本地部署大模型.
本地部署大模型工具
ollama和LM Studio都可以实现本地部署大模型.本文以ollama为例实现一个本地部署访问大模型的例子.
本地部署大模型
运行大模型
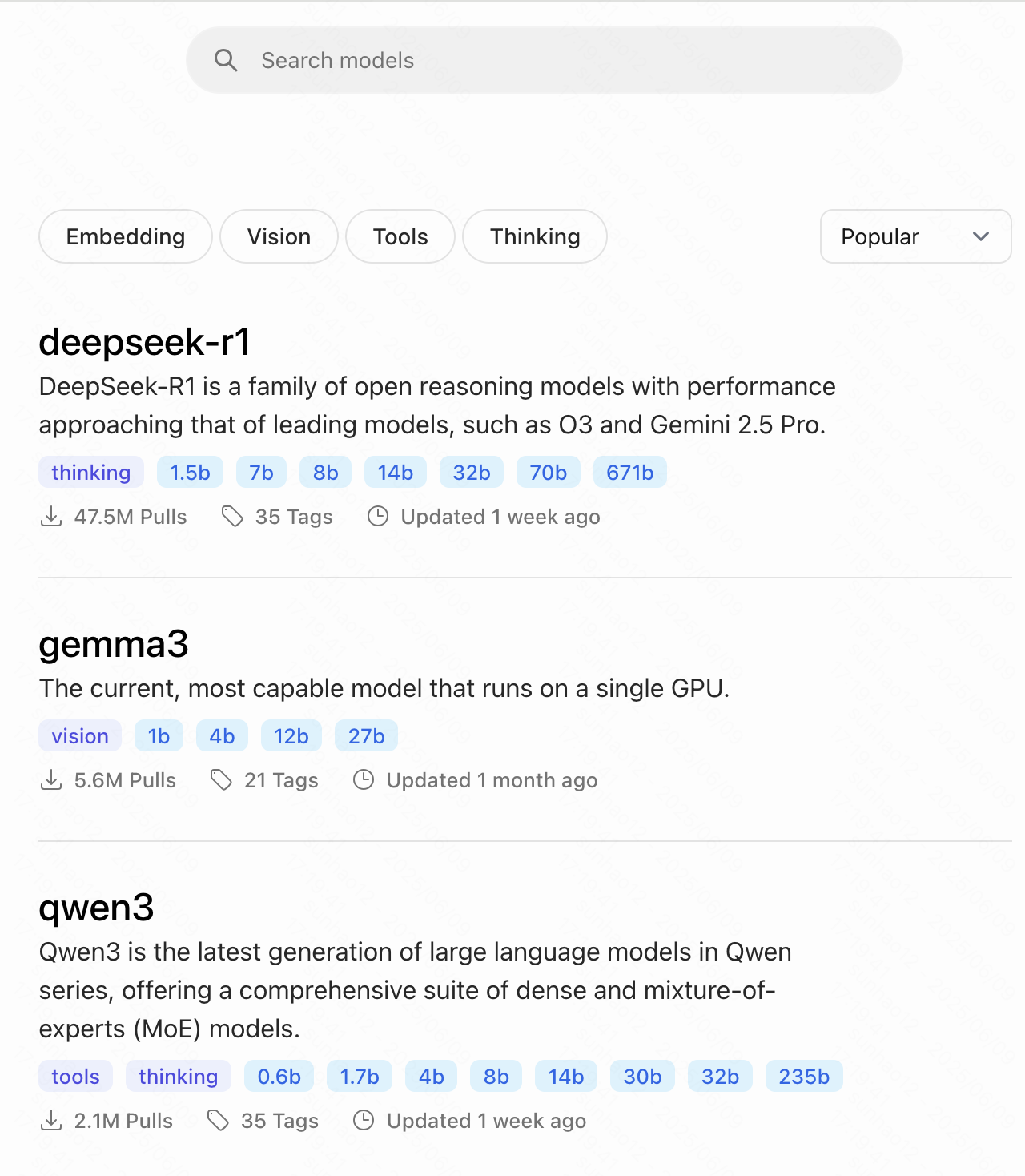 这里选择
这里选择 ollama run deepseek-r1
这个指令就会下载deepseek-r1模型并启动. 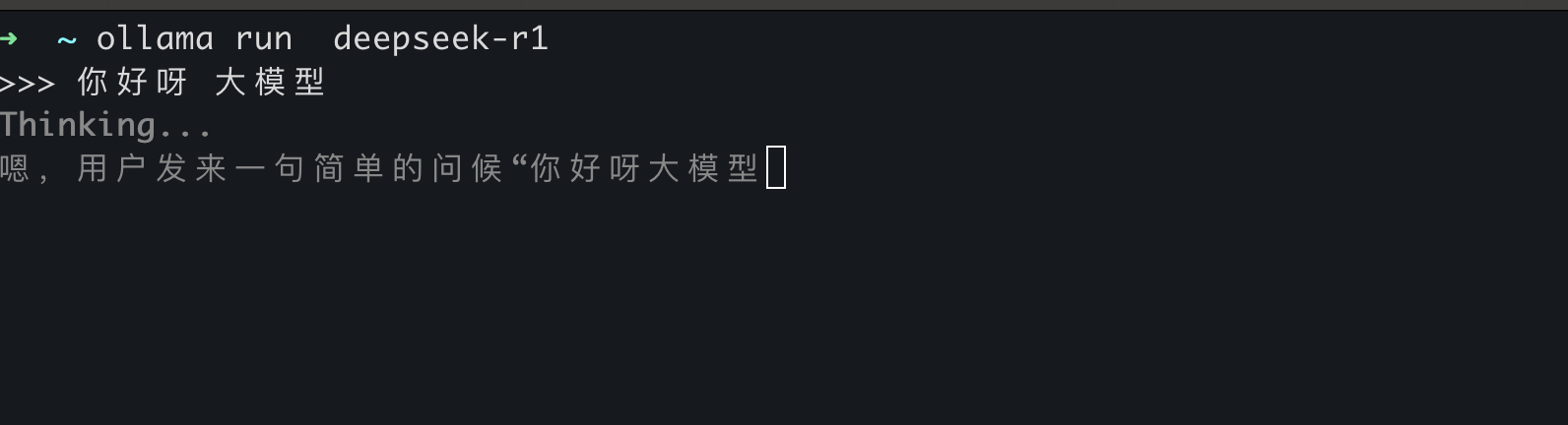
封装访问大模型API
Ollama提供API的方式可以直接跟大模型交互.
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1",
"prompt":"Why is the sky blue?"
}'
这里在之前AI探秘-大模型流式输出是如何实现的的基础上封装接口提供访问大模型的能力. 在服务端可以使用nestjs去封装服务,它提供了装饰器的方式能更简单的实现一个SSE的封装.
// 使用nestjs的装饰器实现SSE的封装
@Sse('stream')
async streamResponse(@Query('prompt') prompt: string): Promise<Observable<MessageEvent>> {
return new Observable<MessageEvent>((subscriber) => {
this.ollamaService.generateResponse(prompt)
.then((stream) => {
stream.on('data', (chunk) => {
const data = JSON.parse(chunk.toString());
subscriber.next({
data: data.response,
type: 'message',
} as MessageEvent);
});
stream.on('end', () => {
subscriber.complete();
});
stream.on('error', (error) => {
subscriber.error(error);
});
})
.catch((error) => {
subscriber.error(error);
});
});
}
// 调用ollama的API生成响应
async generateResponse(prompt: string) {
try {
const response = await axios.post(`${this.baseUrl}/generate`, {
model: 'deepseek-r1',
prompt: prompt,
stream: true,
}, {
responseType: 'stream',
});
return response.data;
} catch (error) {
throw new Error(`Failed to generate response: ${error.message}`);
}
}
页面访问交互
页面的实现相对简单,在点击提交的时候可以通过EventSource访问封装的API服务.在页面中还可以通过选项增加其他大模型的选择. 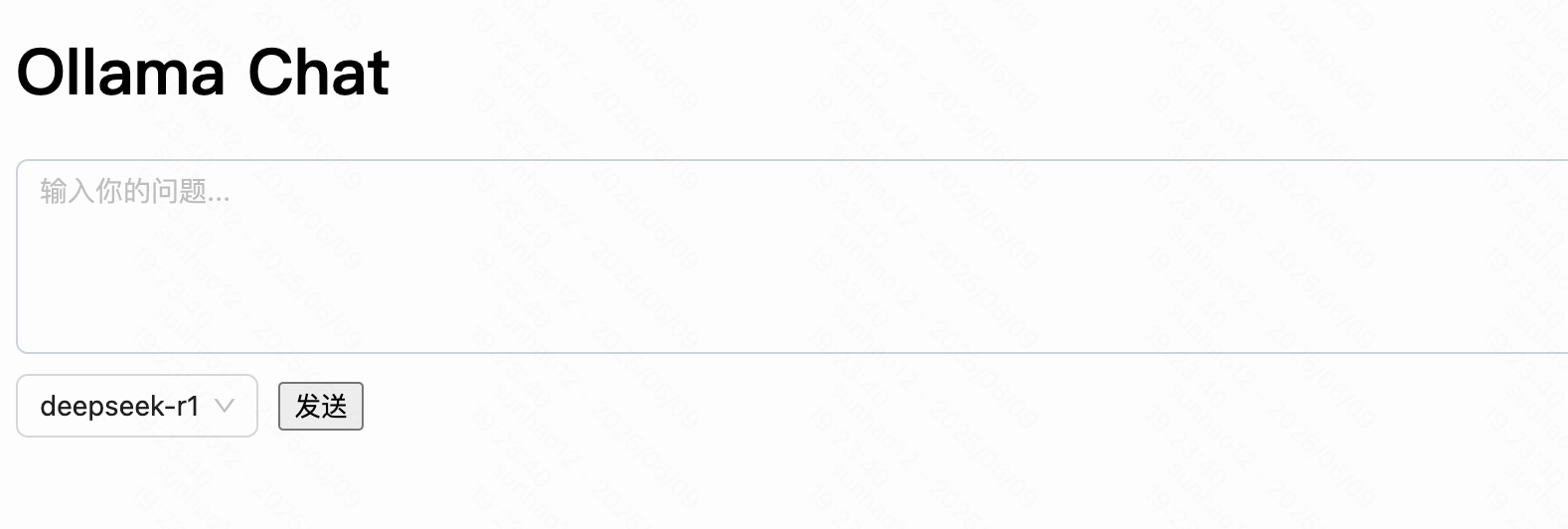
这个是demo的地址,可以参考demo地址