- Published on
AI探秘-理解GPT模型架构
- Authors

- Name
- noodles
- 每个人的花期不同,不必在乎别人比你提前拥有
📚 目录
核心组件
文本生成机制
在本文中主要从GPT(生成式预训练Transformer)模型架构的子模块功能介绍开始,逐步串联整个GPT模型的架构。 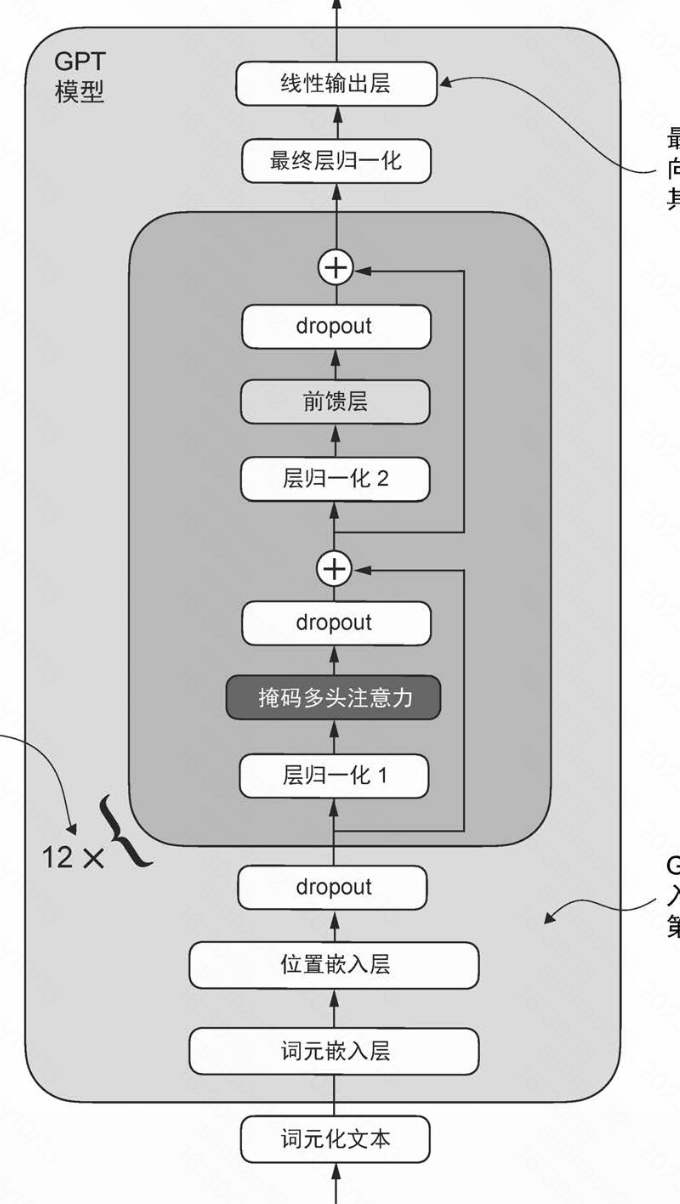 GPT模型整体架构,包含词嵌入、位置编码、多层Transformer块和输出投影层
GPT模型整体架构,包含词嵌入、位置编码、多层Transformer块和输出投影层
GPT模型整体架构,包含词嵌入、位置编码、多层Transformer块和输出投影层层归一化
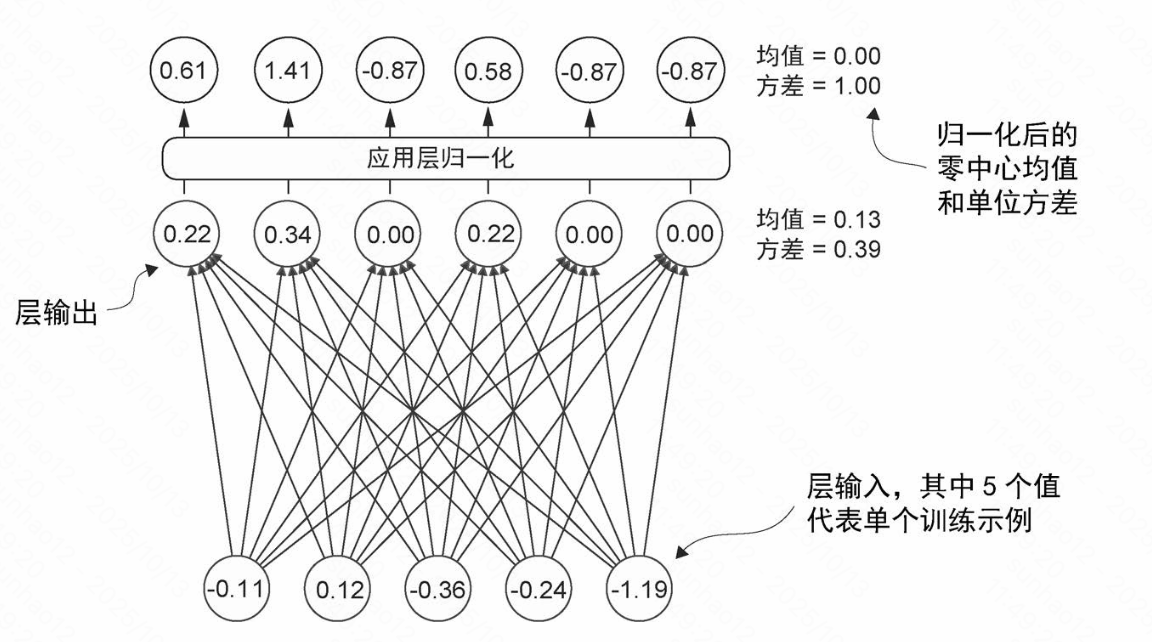
层归一化解决的问题
梯度消失/梯度爆炸问题会导致训练过程不稳定。层归一化通过标准化每层的输入分布,减少内部协变量偏移,从而提高训练的稳定性和收敛速度。
层归一化的位置
层归一化通常采用Pre-LayerNorm方式:分别位于多头注意力和前馈层之前,且在最终输出前有一层。它对每个token的特征维度进行归一化,稳定上下文表示与训练过程。
层归一化实现
层归一化的主要思想是调整神经网络层的输出,使其均值为0且方差(单位方差)为1。
前馈神经网络 (Feed-Forward Neural Network, FFN)
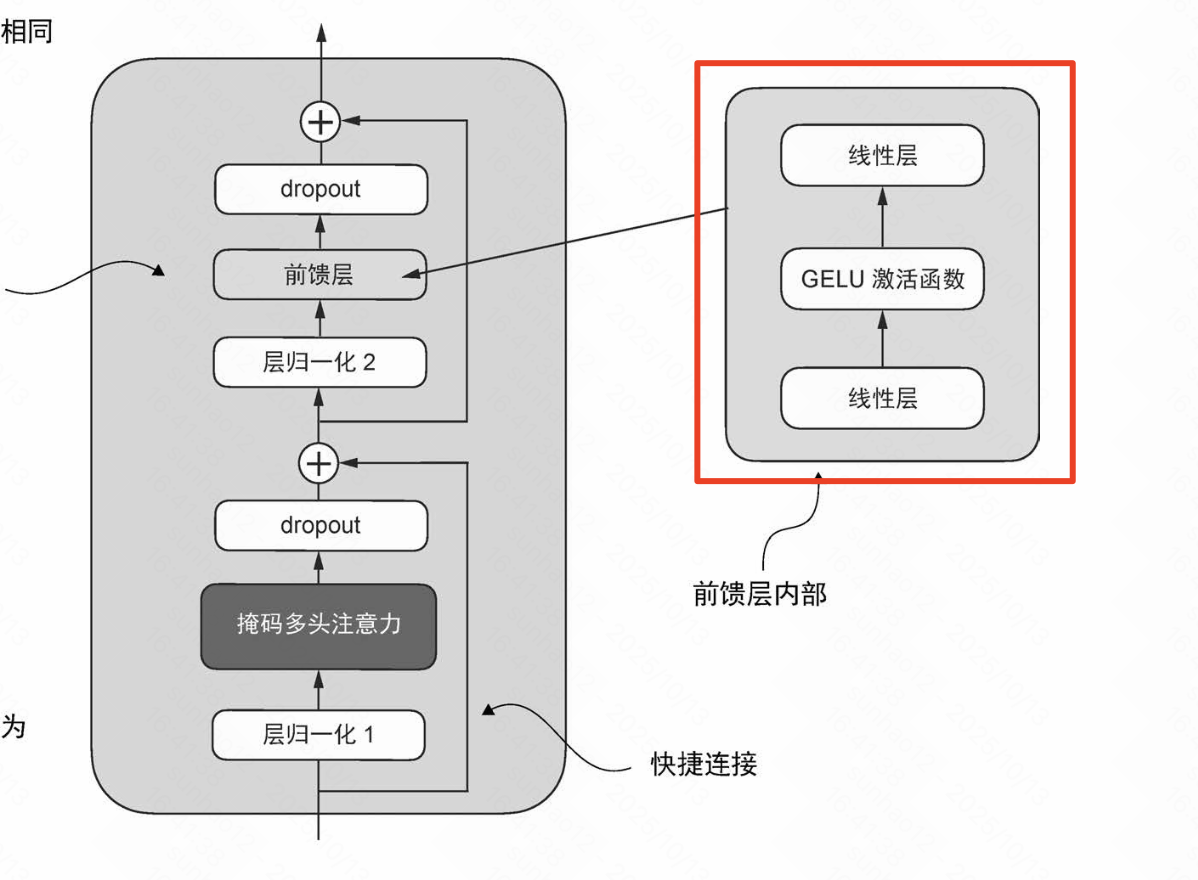
前馈神经网络是神经网络中的一种,在前馈神经网络中:
- 信息只能单向流动:从输入层 → 隐藏层 → 输出层
- 没有循环连接:数据不会回到之前的层
- 顺序处理:每一层只接收前一层的输出
前馈神经网络作用
- 维度扩展:将特征从d_model扩展到4d_model
- 非线性处理:通过GELU激活函数,引入非线性特征
- 压缩:再压缩回d_model维度
激活函数
激活函数可以引入将线性组合的特征转换为非线性特征,从而提高模型的表达能力。
前向传播与反向传播
前向传播
- 数据流向:从输入层流向输出层
- 计算过程:逐层计算每层的输出值
- 目的:得到模型的预测结果
反向传播
- 梯度计算:从输出层向输入层计算梯度
- 链式法则:使用链式法则计算复合函数导数
- 目的:更新网络参数,优化模型
前馈神经网络位置
每个Transformer层都包含一个FFN,位于多头注意力机制之后。
快捷连接(残差连接)
快捷连接(Residual Connection)是深度学习中重要的技术,它可以将输入直接连接到输出,确保各层之间梯度的稳定流动。
残差连接的作用
- 解决梯度消失:让深层网络可以训练
- 提高训练效率:加速收敛过程
- 增强表达能力:网络可以学习恒等映射
- 稳定训练过程:防止梯度爆炸
GPT模型是如何生成文本的
生成文本过程: 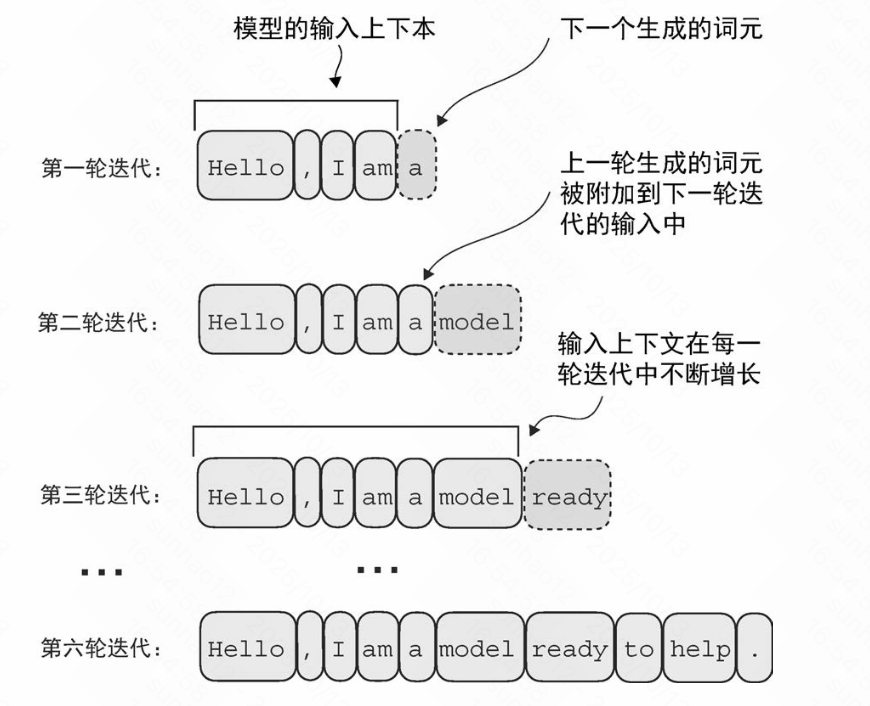
生成文本细节: 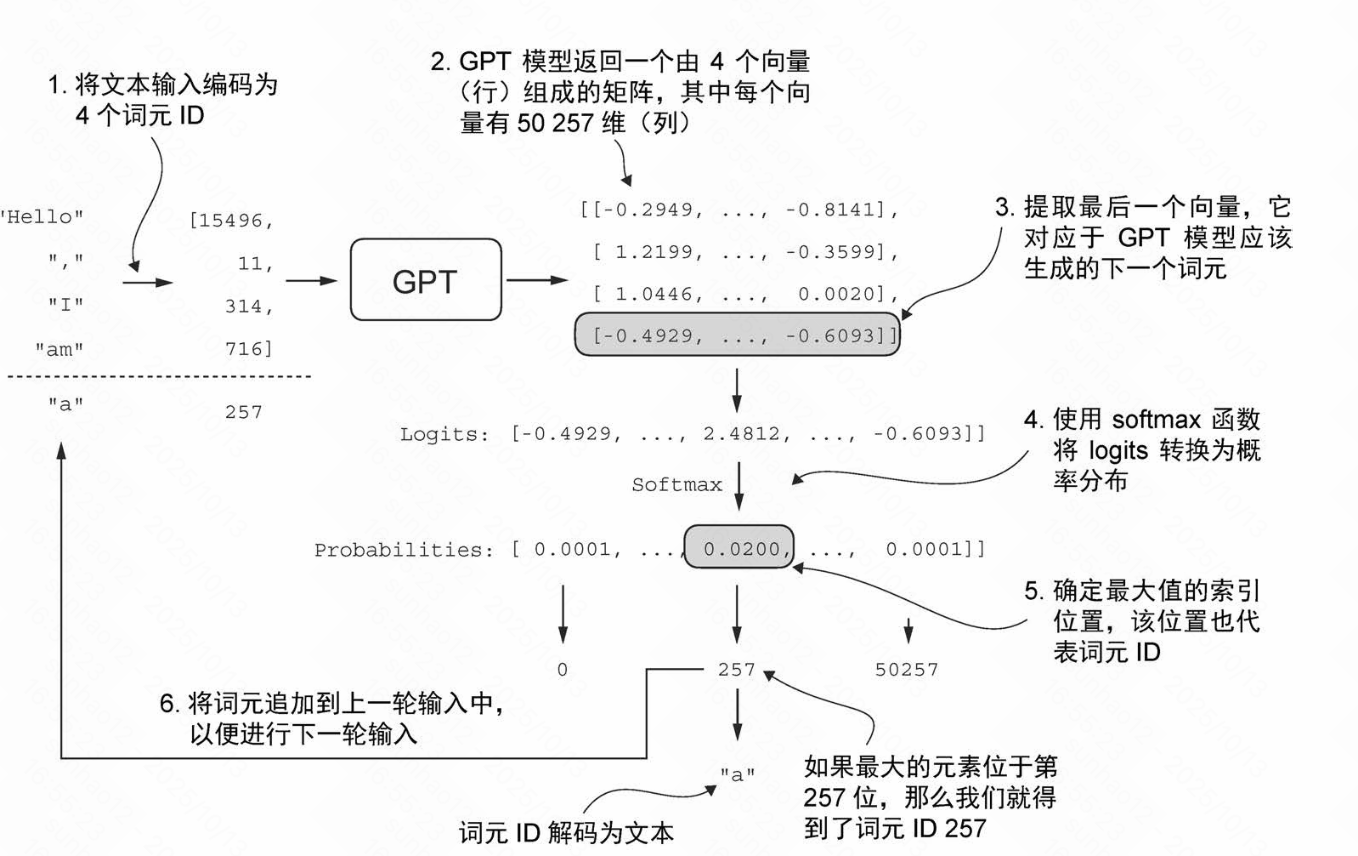
在每一步中,模型输出一个矩阵,其中的向量表示有可能的下一个词元。生成过程如下:
1. 概率计算
- 提取最后一个位置的输出向量(该向量包含了整个序列的上下文信息)
- 将该向量通过输出投影层映射为词表大小的 logits 向量(每个元素对应词表中一个词元的得分)
- 通过 softmax 函数将 logits 转换为概率分布(所有概率和为 1)
2. 词元选择
- 在包含这些概率分数的向量中,找到最高值的索引
- 这个索引对应于词元 ID
3. 序列更新
- 将这个词元 ID 解码为文本,生成序列中的下一个词元
- 将这个词元附加到之前的输入中,形成新的输入序列,供下一次迭代使用
生成文本的退出条件
在训练阶段会在数据中添加特殊标记(如结束标记EOS),模型学习识别这些标记。在生成阶段,当模型生成这些特殊标记时,会根据标记类型来决定是否退出生成过程。 多轮迭代退出条件如下:
- 结束标记:遇到EOS token时退出
- 长度限制:达到最大长度时退出
- 特殊标记:遇到特定标记时退出
- 资源限制:达到计算资源限制时退出
总结
GPT模型通过以下关键组件实现强大的文本生成能力:
- 层归一化:稳定训练过程,解决梯度问题
- 前馈神经网络:扩展特征维度,增强表达能力
- 快捷连接:保持梯度流动,防止梯度消失
- 迭代生成:通过多轮迭代逐步构建完整文本
- 退出机制:通过特殊标记控制生成过程
这些组件协同工作,使GPT能够理解和生成高质量的自然语言文本。